ไวยากรณ์
df [ ( cond_1 ) & ( cond_2 ) ]ตัวอย่าง 01
เราทำรหัสเหล่านี้ในแอพ “Spyder” และจะใช้ตัวดำเนินการ “AND” ในเงื่อนไขของเราใน “pandas” ที่นี่ ในขณะที่เรากำลังทำรหัสแพนด้า ดังนั้นก่อนอื่นเราต้องนำเข้า “pandas เป็น pd” และจะได้รับวิธีการโดยใส่เพียง “pd” ในรหัสของเรา จากนั้นเราสร้างพจนานุกรมชื่อ 'Cond' และข้อมูลที่เราใส่ที่นี่คือ 'A1', 'A2' และ 'A3' เป็นชื่อคอลัมน์และเราเพิ่ม '1, 2 และ 3' ลงใน ' A1' ใน 'A2' มี '2, 6 และ 4' และ 'A3' สุดท้ายประกอบด้วย '3, 4 และ 5'
จากนั้น เรากำลังดำเนินการสร้าง DataFrame ของพจนานุกรมนี้โดยใช้ “pd.DataFrame” ที่นี่ สิ่งนี้จะส่งคืน DataFrame ของข้อมูลพจนานุกรมด้านบน นอกจากนี้เรายังแสดงผลโดยระบุ 'print ()' ที่นี่ และหลังจากนี้ เราใช้เงื่อนไขบางอย่างและใช้ตัวดำเนินการ '&' ในเงื่อนไขนี้ด้วย เงื่อนไขแรกที่นี่คือ “A1 >= 1” จากนั้นเราใส่ตัวดำเนินการ “&” และวางเงื่อนไขอื่นซึ่งก็คือ “A2 < 5” เมื่อเราดำเนินการนี้ มันจะส่งคืนผลลัพธ์หาก “A1 >=1” และ “A2 < 5” ด้วย หากเป็นไปตามเงื่อนไขทั้งสองที่นี่ จะแสดงผลลัพธ์ และหากข้อใดข้อหนึ่งไม่พอใจที่นี่ ก็จะไม่แสดงข้อมูลใดๆ
จะตรวจสอบทั้งคอลัมน์ 'A1' และ 'A2' ของ DataFrame แล้วส่งกลับผลลัพธ์ ผลลัพธ์จะปรากฏบนหน้าจอเนื่องจากเราใช้คำสั่ง 'print ()'
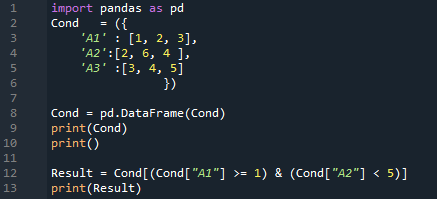
ผลลัพธ์อยู่ที่นี่ จะแสดงข้อมูลทั้งหมดที่เราแทรกใน DataFrame แล้วตรวจสอบทั้งสองเงื่อนไข ส่งคืนแถวที่ “A1 >=1” และ “A2 < 5” ด้วย เราได้สองแถวในผลลัพธ์นี้เนื่องจากทั้งสองเงื่อนไขเป็นที่พอใจในสองแถว
ตัวอย่าง 02
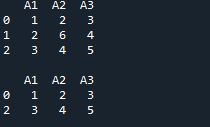
ในตัวอย่างนี้ เราสร้าง DataFrame โดยตรงหลังจากนำเข้า “pandas as pd” DataFrame 'ทีม' ถูกสร้างขึ้นที่นี่ โดยมีข้อมูลที่มีสี่คอลัมน์ คอลัมน์แรกคือคอลัมน์ 'ทีม' ซึ่งเราใส่ 'A, A, B, B, B, B, C, C' จากนั้นคอลัมน์ถัดจาก 'ทีม' คือ 'คะแนน' ซึ่งเราแทรก '25, 12, 15, 14, 19, 23, 25 และ 29' หลังจากนี้ คอลัมน์ที่เรามีคือ 'ออก' และเรายังเพิ่มข้อมูลในคอลัมน์ดังกล่าวเป็น '5, 7, 7, 9, 12, 9, 9 และ 4' คอลัมน์สุดท้ายของเราที่นี่คือคอลัมน์ 'รีบาวด์' ซึ่งมีข้อมูลตัวเลขอยู่ด้วย ซึ่งก็คือ '11, 8, 10, 6, 6, 5, 9 และ 12'
DataFrame เสร็จสมบูรณ์ที่นี่ และตอนนี้เราต้องพิมพ์ DataFrame นี้ ดังนั้นสำหรับสิ่งนี้ เราวาง 'print ()' ไว้ที่นี่ เราต้องการรับข้อมูลบางอย่างจาก DataFrame นี้ ดังนั้นเราจึงกำหนดเงื่อนไขบางอย่างไว้ที่นี่ เรามีสองเงื่อนไขที่นี่ และเราเพิ่มตัวดำเนินการ 'AND' ระหว่างเงื่อนไขเหล่านี้ ดังนั้นมันจะแสดงเฉพาะเงื่อนไขเหล่านั้นที่จะเป็นไปตามเงื่อนไขทั้งสอง เงื่อนไขแรกที่เราได้เพิ่มที่นี่คือ “score > 20” จากนั้นวางตัวดำเนินการ “&” และเงื่อนไขอื่น ๆ ซึ่งก็คือ “Out == 9”
ดังนั้น มันจะกรองข้อมูลที่คะแนนของทีมน้อยกว่า 20 และลึกหนาบางของพวกเขาคือ 9 โดยจะกรองสิ่งเหล่านั้นและละเว้นส่วนที่เหลือ ซึ่งจะไม่เป็นไปตามเงื่อนไขทั้งสองหรือเงื่อนไขใดเงื่อนไขหนึ่ง นอกจากนี้เรายังแสดงข้อมูลเหล่านั้นซึ่งตรงตามเงื่อนไขทั้งสอง ดังนั้นเราจึงใช้วิธี “พิมพ์ ()”
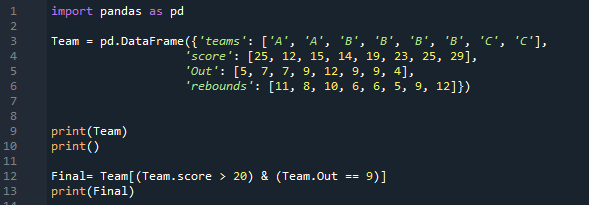
มีเพียงสองแถวเท่านั้นที่ตรงตามเงื่อนไขทั้งสอง ซึ่งเราได้นำไปใช้กับ DataFrame นี้แล้ว มันกรองเฉพาะแถวที่มีคะแนนมากกว่า 20 และลึกหนาบางของพวกเขาคือ 9 และแสดงไว้ที่นี่
ตัวอย่าง 03
ในโค้ดด้านบนนี้ เราเพียงแค่ใส่ข้อมูลตัวเลขลงใน DataFrame ของเรา ตอนนี้ เรากำลังใส่ข้อมูลสตริงในโค้ดนี้ หลังจากนำเข้า “pandas as pd” แล้ว เรากำลังดำเนินการสร้าง DataFrame “สมาชิก” ประกอบด้วยสี่คอลัมน์ที่ไม่ซ้ำกัน ชื่อของคอลัมน์แรกคือ 'ชื่อ' และเราใส่ชื่อสมาชิกซึ่งได้แก่ 'Allies, Bills, Charles, David, Ethen, George และ Henry' คอลัมน์ถัดไปมีชื่อว่า 'Location' และมีคำว่า 'America. แคนาดา ยุโรป แคนาดา เยอรมนี ดูไบ และแคนาดา” คอลัมน์ 'รหัส' ประกอบด้วย 'W, W, W, E, E, E และ E' นอกจากนี้เรายังเพิ่ม “คะแนน” ของสมาชิกที่นี่เป็น “11, 6, 10, 8, 6, 5 และ 12” เราแสดง DataFrame 'สมาชิก' โดยใช้วิธีการ 'พิมพ์ ()' เราได้ระบุเงื่อนไขบางประการใน DataFrame นี้
ในที่นี้ เรามีสองเงื่อนไข และโดยการเพิ่มโอเปอเรเตอร์ “AND” ระหว่างเงื่อนไขเหล่านั้น จะส่งกลับเฉพาะเงื่อนไขที่ตรงตามเงื่อนไขทั้งสองข้อเท่านั้น ในที่นี้ เงื่อนไขแรกที่เราแนะนำคือ “Location == Canada” ตามด้วยโอเปอเรเตอร์ “&” และเงื่อนไขที่สอง “points <= 9” รับข้อมูลเหล่านั้นจาก DataFrame ซึ่งตรงตามเงื่อนไขทั้งสอง จากนั้นเราจึงวาง 'print ()' ซึ่งแสดงข้อมูลซึ่งทั้งสองเงื่อนไขเป็นจริง
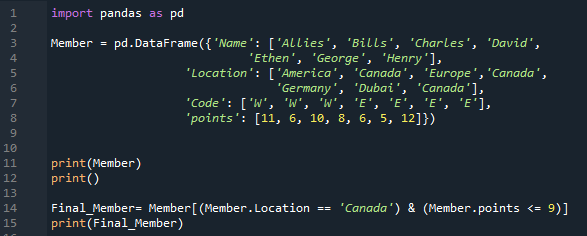
ด้านล่าง คุณจะเห็นว่ามีการแยกแถวสองแถวจาก DataFrame และแสดงขึ้น ในทั้งสองแถว ตำแหน่งคือ 'แคนาดา' และคะแนนน้อยกว่า 9
ตัวอย่าง 04
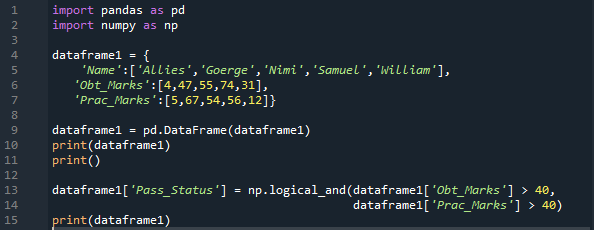
เรานำเข้าทั้ง “pandas” และ “numpy” ที่นี่เป็น “pd” และ “np” ตามลำดับ เราได้รับเมธอด 'pandas' โดยวางเมธอด 'pd' และ 'numpy' โดยวาง 'np' ตามต้องการ จากนั้นพจนานุกรมที่เราสร้างที่นี่จะมีสามคอลัมน์ ในคอลัมน์ 'ชื่อ' เราแทรก 'พันธมิตร จอร์จ นิมิ ซามูเอล และวิลเลียม' ต่อไป เรามีคอลัมน์ 'Obt_Marks' ซึ่งมีคะแนนที่ได้รับของนักเรียน และคะแนนเหล่านั้นคือ '4, 47, 55, 74 และ 31'
นอกจากนี้เรายังสร้างคอลัมน์สำหรับ “Prac_Marks” ที่นี่ซึ่งมีคะแนนการใช้งานจริงของนักเรียน เครื่องหมายที่เราเพิ่มในที่นี้คือ “5, 67, 54, 56 และ 12” เราสร้าง DataFrame ของพจนานุกรมนี้แล้วพิมพ์ออกมา เราใช้ 'np.Logical_and' ที่นี่ ซึ่งจะส่งคืนผลลัพธ์ในรูปแบบ 'จริง' หรือ 'เท็จ' เรายังจัดเก็บผลลัพธ์หลังจากตรวจสอบทั้งสองเงื่อนไขในคอลัมน์ใหม่ ซึ่งเราได้สร้างไว้ที่นี่ด้วยชื่อ “Pass_Status”
ตรวจสอบว่า “Obt_Marks” มากกว่า “40” และ “Prac_Marks” มากกว่า “40” หากทั้งคู่เป็นจริง ก็จะแสดงผลจริงในคอลัมน์ใหม่ มิฉะนั้นจะทำให้เป็นเท็จ
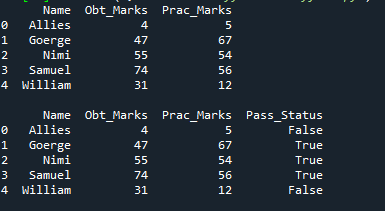
คอลัมน์ใหม่ถูกเพิ่มด้วยชื่อ 'Pass_Status' และคอลัมน์นี้ประกอบด้วย 'True' และ 'False' เท่านั้น โดยจะแสดงเป็นจริงโดยที่เครื่องหมายที่ได้รับและเครื่องหมายที่ใช้ได้จริงมีค่ามากกว่า 40 และเป็นเท็จสำหรับแถวที่เหลือ
บทสรุป
เป้าหมายหลักของบทช่วยสอนนี้คือการอธิบายแนวคิดของ 'และเงื่อนไข' ใน 'แพนด้า' เราได้พูดถึงวิธีรับแถวเหล่านั้นเมื่อตรงตามเงื่อนไขทั้งสอง หรือเรายังได้รับจริงสำหรับผู้ที่ตรงตามเงื่อนไขทั้งหมดและเป็นเท็จสำหรับส่วนที่เหลือ เราได้สำรวจสี่ตัวอย่างที่นี่ ตัวอย่างทั้งสี่ที่เราสร้างไว้ในบทช่วยสอนนี้ได้ผ่านกระบวนการนี้แล้ว ตัวอย่างในบทช่วยสอนนี้ได้รับการนำเสนออย่างรอบคอบเพื่อประโยชน์ของคุณ บทช่วยสอนนี้ควรช่วยคุณในการทำความเข้าใจแนวคิดนี้ให้ชัดเจนยิ่งขึ้น