“Pandas” เป็นเครื่องมือที่มีประสิทธิภาพสูงสำหรับสภาพแวดล้อมของหลาม เป็นซอร์สโค้ด 'เปิด' สำหรับการวิเคราะห์ข้อมูล การรวมแพนด้าและวิธีการผสานแพนด้าใช้สำหรับการรวมดาต้าเฟรมทั้งสองเข้าด้วยกันเป็นดาต้าเฟรมเดียว ในทั้งสองวิธีของแพนด้า ความแตกต่างคือฟังก์ชัน 'เข้าร่วม' ของแพนด้าจะเข้าร่วมดาต้าเฟรมโดยใช้ดัชนี ในขณะที่ฟังก์ชัน 'ผสาน' ของแพนด้ารวม dataframe โดยใช้ดัชนีและวิธีคอลัมน์ที่เราสามารถเลือกคอลัมน์ที่ต้องการได้ด้วยตนเอง วิธีการรวมของแพนด้าส่วนใหญ่จะใช้เมื่อเปรียบเทียบกับวิธีการรวมของแพนด้า ซอฟต์แวร์ที่เราจะใช้ในการปรับใช้คือซอฟต์แวร์ 'สปายเดอร์' ซึ่งอยู่ในสภาพแวดล้อมของหลามที่จะให้ประโยชน์แก่เราสำหรับการติดตั้งโค้ดของเมธอด pandas join () และฟังก์ชันเมธอด pandas merge ()
ไวยากรณ์ของ Pandas Join() Method
“df1. เข้าร่วม ( df2 ) ”“df” ในไวยากรณ์ด้านบนเป็นตัวย่อของ “dataframe” มีสองดาต้าเฟรมในไวยากรณ์ที่มีฟังก์ชัน 'dot join' ซึ่งใช้สำหรับเรียกเมธอด เป็นวิธีการของแพนด้าในการรวมสองดาต้าเฟรม ทำงานโดยใช้ดัชนีเพื่อรวม dataframes ไว้ในอันเดียว
ไวยากรณ์ของ Pandas Merge() Method
“df1. ผสาน ( df2 , บน = 'column_name' ) ”ไวยากรณ์วิธีการรวมแพนด้ามีสองดาต้าเฟรมเป็น “df1” และ “df2” ฟังก์ชัน 'dot merge' เรียกวิธีการรวม dataframe ทั้งสองเข้าด้วยกันโดยมีลักษณะของคอลัมน์กลับด้าน
เราจะกล่าวถึงวิธีการรวมสอง dataframes ต่อไปนี้เพื่อใช้วิธีการรวมแพนด้าและการรวมแพนด้า:
- Pandas เข้าร่วมวิธีการซ้อนทับกัน
- Pandas เข้าร่วมวิธีการโดยใช้การรีเซ็ตดัชนี
- วิธีการรวม Pandas (คอลัมน์ 'ซ้ายและขวา')
- วิธีการผสานของ Pandas อย่างชัดเจน
การสร้างดาต้าเฟรมสำหรับการปรับใช้ Pandas Merge และ Pandas Join Method
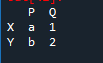
ขั้นแรก เราต้องสร้าง data frame สำหรับสิ่งนั้น เราจะใช้เครื่องมือ 'สไปเดอร์' หลังจากเปิดแล้วให้เริ่มเขียนโค้ด นำเข้าแพนด้าเป็น “pd” สำหรับสมาคมห้องสมุดแพนด้า เรามีตัวแปร dataframe เป็น 'x', 'y', 'p' และ 'q ตามลำดับและ 'a' ที่มีค่า '1' และ 'b' โดยมีค่ากำหนดเป็น '2'

ผลลัพธ์คือ “df” ที่สร้างขึ้นด้วยค่าที่กำหนด เราสามารถทำให้มันใหญ่เท่ากับข้อมูล
การสร้าง Dataframe อื่น
เราต้องสร้างดาต้าเฟรมใหม่ เพื่อให้เข้าใจวิธีการรวมแพนด้าและการรวมแพนด้าอย่างชัดเจน ที่นี่เรามี 'df' ที่สร้างขึ้นเหมือนกับ 'df' ด้านบน เฉพาะค่าที่เป็นตัวแปรที่กำหนดเท่านั้นที่แตกต่างกัน เรามี 'h', 'j', 's' และ 'd' ในขณะที่กำหนดค่า 'b' ด้วยค่า '8' และ 'Y' ด้วยค่า '3'

ผลลัพธ์แสดง “df” แบบง่าย ๆ ที่สร้างขึ้น

ตัวอย่าง # 01: วิธีเข้าร่วม Pandas (ทับซ้อนกัน)
ตอนนี้เราจะมาดูวิธีการเชื่อมสอง dataframes กับ pandas join method สำหรับวิธีนี้ เราสามารถเลือกคอลัมน์ที่คุณต้องการใช้จากดาต้าเฟรมได้ เราได้นำตัวอย่างที่มีคอลัมน์ 'ซ้าย' ที่ทับซ้อนกันจาก 'df' มาใช้ ดังนั้นเราจึงสามารถแก้ไขปัญหานี้ด้วย 'ส่วนต่อท้าย' เพื่อเอาชนะการทับซ้อนของข้อมูล ในที่นี้ตัวแปรที่ใช้คือ 'x', 'z', 'v', 'd' “p”, “o”, “l” และ “y” ด้วยค่าที่กำหนดเป็น “3”, “6”, “7” และ “9” '.join' เรียกเมธอด โดยการจัดแนวให้เข้าร่วมด้านซ้ายพร้อมกับส่วนต่อท้าย 'df' ที่ถูกต้อง ” “คำต่อท้าย” ที่ใช้ในโค้ดนั้นเป็นเพราะใน dataframe มีสองคอลัมน์ที่มีชื่อเดียวกันคือ “key” และจะไม่ทับซ้อนข้อมูล
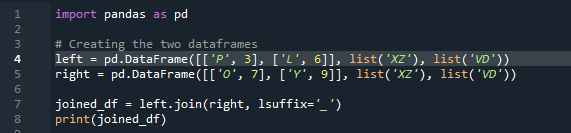
ผลลัพธ์ไม่แสดงข้อมูลที่ทับซ้อนกันด้วยวิธีการรวมสอง “df” โดยใช้วิธีการเข้าร่วมแพนด้า
ตัวอย่าง # 02: วิธีเข้าร่วม Pandas โดยใช้การรีเซ็ตดัชนี
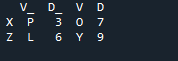
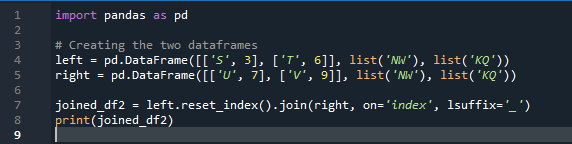
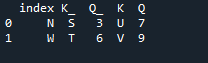
ในตัวอย่างนี้ เราจะแยกการระบุคอลัมน์ที่มีพารามิเตอร์ 'เปิด' เพื่อใช้เป็น 'คีย์' ในการเข้าร่วมเมธอดที่ช่วยในการเข้าร่วมดาต้าเฟรมทั้งสอง สิ่งที่รวมกันจะทำกับพารามิเตอร์นี้ นอกจากนี้ ดัชนีของหนึ่งในสอง “df” ควรมีความคล้ายคลึงในการรวมเข้าด้วยกัน ข้อมูลประเภทเดียวกันหรือข้อมูลที่ใช้เพื่อวัตถุประสงค์เดียวกันสามารถนำมาประมวลผลร่วมกันได้ นี้จะใช้ดัชนียังคงใช้จากด้านขวา ตัวแปรได้แก่ “s”, “t”, “u”, “v”, “n”, ‘w”, “k” และ “q” ค่าที่กำหนดคือ “3”, “6”, “7” และ “9” 'รีเซ็ตดัชนีจุด' เป็นวิธีการของแพนด้าเพื่อรีเซ็ตดัชนีของ 'df' ดัชนีรีเซ็ตจะตั้งค่าจำนวนเต็มทั้งหมดของรายการดาต้าเฟรมของคุณตั้งแต่ 0 จนกว่าข้อมูลดาต้าเฟรมจะยาวขึ้น
นี่คือผลลัพธ์ที่แสดงด้วยวิธีการเข้าร่วมดัชนี 'คีย์' ของแพนด้า
ตัวอย่าง # 03: Pandas Merge Method (คอลัมน์ 'ซ้ายและขวา')
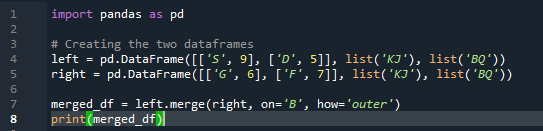
วิธีการผสานทำงานคล้ายกับวิธีการรวมแพนด้า ทั้งสองวิธีใช้สำหรับการรวมข้อมูลใน dataframe ที่คล้ายคลึงกัน วิธีการผสานมีความหลากหลายมากขึ้นโดยต้องระบุคีย์ นอกจากนี้เรายังสามารถระบุได้ในคอลัมน์ด้านซ้ายและขวาขึ้นอยู่กับงานของ dataframe ของคุณ ตัวแปรในโค้ดคือ 's', 'd', 'g', 'f', 'k', 'j', 'b' และ 'q' ค่าที่กำหนดคือ “9”, “5”, “6” และ “7” การใช้งาน 'join' ภายนอกทำได้ทั้งบน 'df' โดยใช้พารามิเตอร์ 'how' ของฟังก์ชันวิธีการผสานแพนด้า
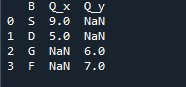
ผลลัพธ์ที่เราเห็นแสดงข้อมูลที่ผสานของสอง dataframes 'NaN' หมายถึง 'ไม่ใช่ตัวเลข' ซึ่งหมายความว่าเมื่อไม่มีการกำหนดตัวเลขในข้อมูล 'NaN' จะแสดงที่นั่น
ตัวอย่าง # 04: วิธีการผสานอย่างชัดเจน
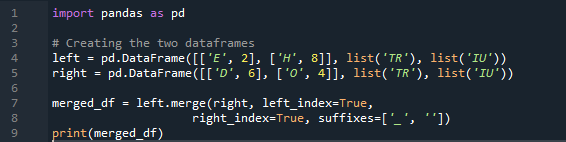
ในที่นี้ ในตัวอย่างนี้ วิธีการผสานคือการทำลายดัชนีและค่าดัชนีจะไม่ถูกสันนิษฐานในดาต้าเฟรม เราจะใช้วิธีนี้ตามงานที่จำเป็นต้องทำ โดยระบุให้ชัดเจนเพื่อติดตามผล จะผสานข้อมูลตามดัชนีด้านซ้ายหรือดัชนีด้านขวากับพารามิเตอร์ ตัวแปรในดาต้าเฟรมนี้คือ 't', 'r', 'I', 'u', 'h', 'o', 'e' และ 'e' ค่าที่กำหนดคือ “2”, “4”, “6” และ “4” ตัวอย่างข้างต้นของวิธีการผสานแพนด้ากับการเลือกคอลัมน์ตามความต้องการเป็นวิธีที่เรียบร้อยและมีค่าที่สุดในการเข้าร่วมดาต้าเฟรมทั้งสอง ตรวจสอบที่ส่วนท้ายของโค้ดเกี่ยวกับคีย์การผสานที่ไม่ซ้ำในชุดข้อมูล
ในผลลัพธ์ด้านล่าง ดัชนีจะไม่แสดงโดยไม่มีดัชนี แต่ฟังก์ชันจะดำเนินการตามดัชนีด้านขวาและด้านซ้าย
บทสรุป
merge() และ join() วิธีการทั้งสองวิธีที่สะดวกและมีประสิทธิภาพมาก ฟังก์ชันทั้งสองนี้ใช้สำหรับเชื่อม dataframe แยกกันสอง dataframe บน dataframe เดียวกัน แต่มีการใช้งานที่แตกต่างกันขึ้นอยู่กับกรณี ในบทความนี้ เราได้เรียนรู้ความแตกต่างที่สำคัญระหว่างวิธีการเข้าร่วมแพนด้าและการรวม หลังจากทำตัวอย่างและเข้าใจวิธีการเข้าร่วมแพนด้าแล้ว เราจะสรุปด้วยความรู้ว่าหากต้องการการรวมรูปแบบฐานข้อมูลที่ยืดหยุ่นมากขึ้น ควรใช้วิธีการรวมแพนด้า ในทางกลับกัน หากเราต้องการสร้าง dataframe ร่วมกับ index อย่างกว้างขวาง เราก็สามารถใช้ฟังก์ชันเมธอด pandas join() ได้