Amazon Redshift เป็นโซลูชันระบบคลาวด์ที่นำเสนอโดย AWS ซึ่งตอบสนองวัตถุประสงค์ของคลังข้อมูล คลังข้อมูลเป็นพื้นที่ขนาดใหญ่ในระบบคลาวด์ที่จัดเก็บข้อมูลจำนวนมหาศาล ความแตกต่างระหว่างคลังข้อมูลและฐานข้อมูลคือคลังข้อมูลเดิมไม่ได้เก็บข้อมูลปัจจุบันเท่านั้น แต่ยังรวมถึงประวัติทั้งหมดของข้อมูลด้วย
บทความนี้จะเรียนรู้เกี่ยวกับ Amazon Redshift โดย AWS และประเภทข้อมูลที่บริการนี้รองรับ
Amazon RedShift คืออะไร
เป็นโซลูชันคลาวด์สำหรับคลังข้อมูลที่อิงตาม 'โพสต์เกรสคิวแอล' . โดยใช้เทคโนโลยีที่เรียกว่า 'การประมวลผลแบบขนานจำนวนมาก (MPP)' เพื่อประมวลผลข้อมูลระดับเพตะไบต์ด้วยความเร็วสูง นี่เป็นวิธีแก้ปัญหาที่ง่ายสำหรับการทำนายตามเวลาจริงโดยอิงตามข้อมูลในอดีตและโซลูชันการสตรีม
รูปต่อไปนี้แสดงกลไกการทำงานของ Amazon Redshift:
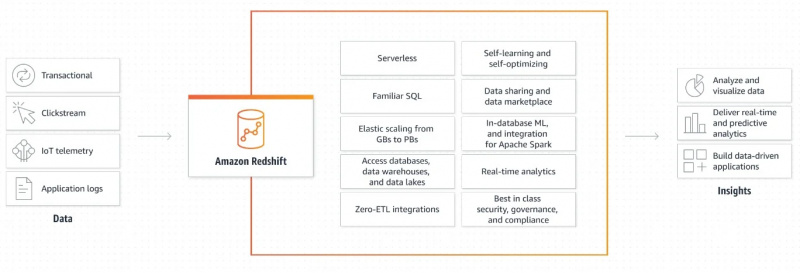
คำอธิบายแบบกราฟิกเกี่ยวกับวิธีการทำงานของ Amazon Redshift นั้นเรียบง่ายและชัดเจนมาก ข้อมูลนี้ให้ข้อมูลเกี่ยวกับวิธีการดึงข้อมูลและประมวลผลเพิ่มเติมเพื่อสร้างเอาต์พุตและสร้างแอปพลิเคชันที่ขับเคลื่อนด้วยข้อมูล
สถาปัตยกรรมคลังข้อมูลของ Amazon Redshift ยังสามารถเห็นได้ในรูปด้านล่าง:
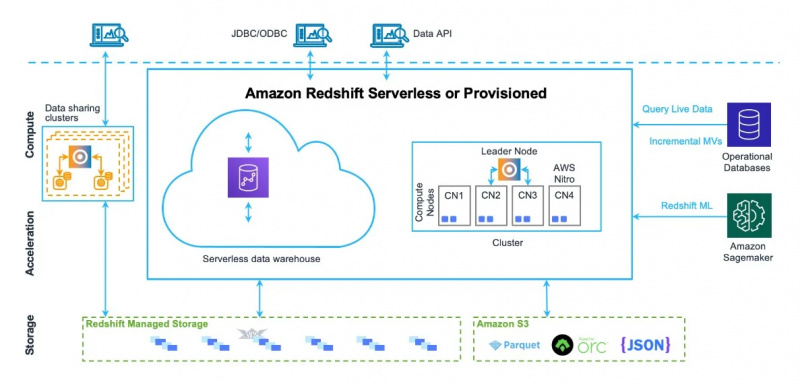
ตอนนี้เราจะไปที่การใช้งานและคุณสมบัติของบริการนี้
คุณสมบัติ
ตามที่ได้กล่าวไปแล้ว Amazon Redshift ใช้ PostgreSQL และใช้เทคโนโลยีที่เรียกว่า Massively Parallel Processing ซึ่งช่วยให้สามารถประมวลผลข้อมูลขนาดเพตะไบต์ได้ในเวลาไม่นาน ดังนั้น Redshift จึงมีคุณสมบัติและการใช้งานที่ดีมากมาย คุณสมบัติบางอย่างอยู่ด้านล่าง:
- ความปลอดภัยของข้อมูลและการเข้ารหัส
- การวิเคราะห์ธุรกิจ
- การสนับสนุนแอปพลิเคชันที่ขับเคลื่อนด้วยข้อมูล
- การวิเคราะห์เชิงคาดการณ์
- การทำซ้ำงานอัตโนมัติ
- การปรับขนาดข้อมูลพร้อมกัน
- คลังข้อมูล.
คุณลักษณะพิเศษบางอย่างของบริการนี้สามารถเห็นได้จากรูปด้านล่าง:
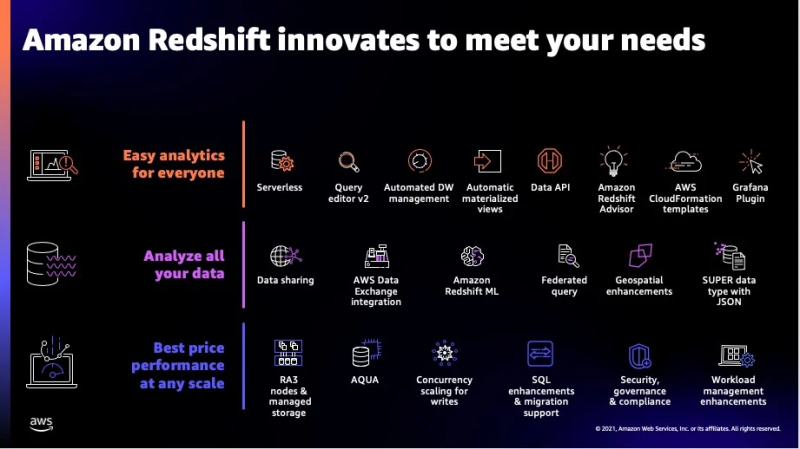
นี่คือคุณสมบัติส่วนใหญ่ที่ Redshift นำเสนอ และตอนนี้เราจะย้ายไปยังประเภทข้อมูลที่บริการนี้รองรับ
ประเภทข้อมูล
Amazon Redshift เป็นโซลูชันคลังข้อมูลที่มีคุณสมบัติมากมาย รองรับทั้งประเภทข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง เนื่องจากใช้ PostgreSQL ข้อมูลจึงสามารถจัดการได้ผ่านการสืบค้น SQL อย่างง่าย
ตอนนี้มีคำถามเกิดขึ้นอีก เช่น รูปแบบข้อมูลเหล่านี้แตกต่างกันอย่างไร ให้เราหารือเกี่ยวกับรูปแบบข้อมูลทั้งสองนี้
ข้อมูลที่มีโครงสร้าง
ประเภทข้อมูลที่มีรูปแบบสูงซึ่งแปลได้ง่ายโดยอัลกอริทึมการเรียนรู้ของเครื่องเรียกว่าข้อมูลที่มีโครงสร้าง ฐานข้อมูล SQL ทำงานร่วมกับข้อมูลที่มีโครงสร้าง ข้อมูลที่มีโครงสร้างอยู่ในรูปแบบตาราง เช่น ข้อมูลที่ใช้โดยฐานข้อมูลเชิงสัมพันธ์
หนึ่งในระบบจัดการฐานข้อมูล SQL ที่ใช้กันอย่างแพร่หลายคือ MYSQL สถาปัตยกรรมของมันสามารถดูได้ด้านล่างในรูปที่กำหนด:
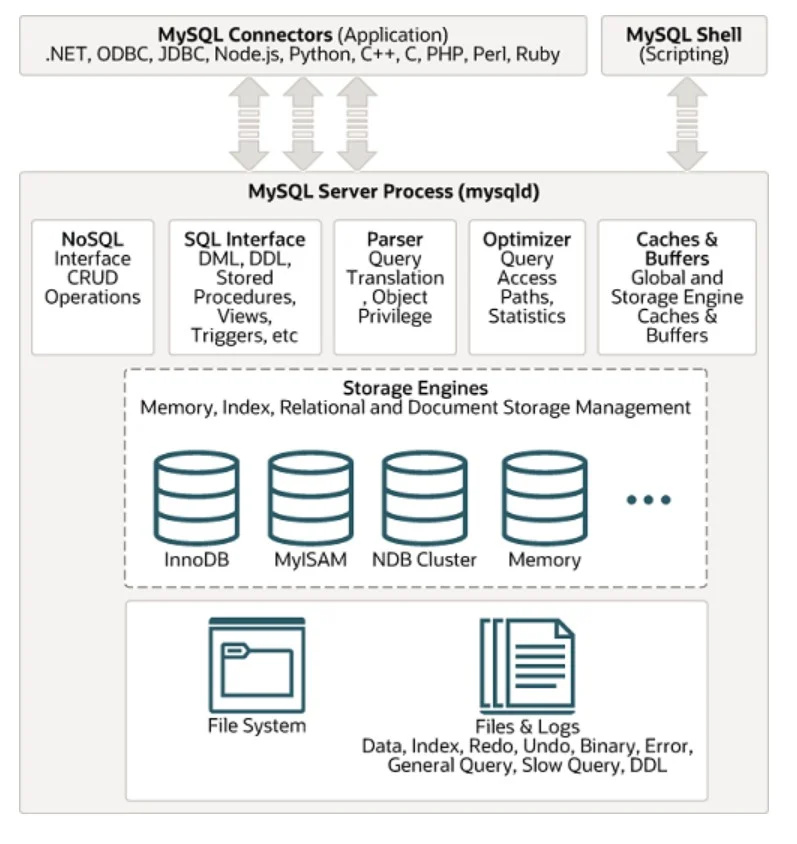
ข้อมูลที่ไม่มีโครงสร้าง
ข้อมูลที่ไม่มีโครงสร้างมีรูปแบบน้อยลงและจัดรูปแบบข้อมูลน้อยลง เช่น ข้อมูลที่ใช้ในฐานข้อมูลที่ไม่ใช่เชิงสัมพันธ์ MongoDB เป็นฐานข้อมูลที่ไม่เกี่ยวข้องที่มีชื่อเสียง แบบสอบถาม SQL ไม่ทำงานบนฐานข้อมูลที่ไม่ใช่เชิงสัมพันธ์ ดังนั้นฐานข้อมูลเหล่านี้จึงเรียกอีกอย่างว่าฐานข้อมูล NoSQL
ดังที่กล่าวไปแล้ว MongoDB เป็นระบบจัดการฐานข้อมูลแบบไม่มีโครงสร้าง และสถาปัตยกรรมของมันสามารถดูได้ด้านล่างในรูปที่กำหนด:
เราได้ศึกษาประเภทข้อมูลพื้นฐานสองประเภทที่ใช้ในฐานข้อมูลแล้ว และตอนนี้เราจะไปที่ประเภทข้อมูลจริงที่ Amazon Redshift รองรับ ประเภทข้อมูลเหล่านี้คือ:
- ข้อมูลตัวเลข
- ข้อมูลตัวละคร
- ข้อมูลวันที่และเวลา
- ข้อมูลบูลีน
- ข้อมูล HLLSKETCH
- สุดยอดข้อมูล
- เปลี่ยนข้อมูล
ให้เราหารือเกี่ยวกับประเภทข้อมูลเหล่านี้:
ข้อมูลตัวเลข
ชนิดข้อมูลนี้เป็นตัวอธิบาย รองรับข้อมูลที่อยู่ในรูปของจำนวนเต็ม ทศนิยม ทศนิยม และข้อมูลประเภทตัวเลขอื่นๆ
ลักษณะของข้อมูลชนิดจำนวนเต็มสามารถดูได้จากรูปด้านล่าง
ข้อมูลประเภททศนิยมจะเก็บข้อมูลตามความแม่นยำของผู้ใช้ ลักษณะของมันมีดังนี้:

ข้อมูลตัวละคร
ประเภทข้อมูล CHAR และ VARCHAR อยู่ภายใต้หมวดหมู่ของประเภทข้อมูลแบบอักขระ NCHAR และ NVARCHAR เป็นประเภทข้อมูลประเภทอักขระด้วย ซึ่งแตกต่างจาก CHAR และ VARCHAR ข้อมูลทั้งสองประเภทนี้จัดเก็บอักขระ Unicode ที่มีความยาวคงที่ ให้เราดูคุณสมบัติของประเภทข้อมูลเหล่านี้ เช่น:
- CHAR, CHARACTER, NCHAR มีช่วง 4KB
- VARCHAR, NVARCHAR มีช่วง 64KB
- BPCHAR มีช่วง 256 ไบต์
- TEXT มีช่วง 260 ไบต์
ข้อมูลวันที่และเวลา
ชนิดข้อมูลวันที่และเวลาคือ DATE, TIME, TIMETZ,TIMESTAMP, TIMESTAMPTZ ความสามารถในการทำงานของชนิดข้อมูลเหล่านี้มีดังนี้:
- DATE เพียงแค่เก็บวันที่ในปฏิทิน
- TIME เก็บเวลาโดยไม่อ้างอิงโซนเวลาใดๆ เป็น UTC ตามค่าเริ่มต้น
- TIMETZ เก็บเวลาโดยอ้างอิงจากโซนเวลา เป็น UTC ทั้งในตารางผู้ใช้และตารางระบบตามค่าเริ่มต้น
- TIMESTAMP ไม่เพียงแต่รวมเวลา แต่ยังรวมถึงวันที่ด้วย เป็น UTC ทั้งในตารางผู้ใช้และตารางระบบ ตามค่าดีฟอลต์
- TIMESTAMPTZ ไม่เพียงแต่รวมเวลา แต่ยังรวมถึงวันที่ด้วย เป็น UTC ในตารางผู้ใช้เท่านั้น ตามค่าเริ่มต้น
ข้อมูลบูลีน
ประเภทข้อมูลบูลีนเป็นประเภทข้อมูลไบนารี ซึ่งหมายความว่ามีเพียงสองค่าเท่านั้น ตารางคุณลักษณะสำหรับประเภทข้อมูลบูลีนแสดงไว้ด้านล่างในรูป:
ข้อมูล HLLSKETCH
ชนิดข้อมูลนี้ใช้เพื่อจัดเก็บภาพร่าง Redshift สามารถแสดงภาพสเก็ตช์ได้ทั้งแบบเบาบางหรือหนาแน่น ภาพร่างเริ่มเป็นแบบเบาบางและค่อย ๆ กลายเป็นแบบหนาแน่นเมื่อรูปแบบแบบหนาแน่นมีประสิทธิภาพมากขึ้นโดยไปที่ลิงก์
สุดยอดข้อมูล
ข้อมูลประเภทนี้เกี่ยวข้องกับข้อมูลที่ไม่มีโครงสร้างซึ่งอาจอยู่ในรูปแบบของอาร์เรย์ โครงสร้างซ้อน หรือ JSON ไม่มีแบบจำลองหรือรูปแบบของข้อมูล ผู้ใช้สามารถสำรวจข้อมูลเพิ่มเติมได้โดยไปที่ลิงก์
เปลี่ยนข้อมูล
ชนิดข้อมูลนี้ยังเก็บอักขระ อย่างไรก็ตาม ความยาวมีจำกัด Amazon Redshift อนุญาตให้ส่งข้อมูล VARBYTE เป็นข้อมูลประเภทจำนวนเต็มหรือประเภทอักขระ หากต้องการข้อมูลเพิ่มเติมเกี่ยวกับประเภทข้อมูลนี้ โปรดไปที่ลิงก์ด้านล่าง
นี่คือทั้งหมดที่มีใน Amazon Redshift และประเภทข้อมูลที่รองรับ
บทสรุป
Amazon Redshift เป็นบริการของ AWS ที่อยู่ในรูปแบบพื้นฐานเพื่อวัตถุประสงค์ของคลังข้อมูล แต่เป็นโซลูชันที่ทรงพลังและมีฟีเจอร์สำหรับการวิเคราะห์และการคาดคะเน บทความนี้กล่าวถึง Redshift และประเภทข้อมูลที่สนับสนุน ชนิดข้อมูลเหล่านี้ได้รับการอธิบายสั้น ๆ พร้อมกับลักษณะเฉพาะ