คู่มือนี้จะแสดงวิธีใช้ VectorStoreRetrieverMemory โดยใช้เฟรมเวิร์ก LangChain
จะใช้ VectorStoreRetrieverMemory ใน LangChain ได้อย่างไร
VectorStoreRetrieverMemory คือไลบรารีของ LangChain ที่สามารถใช้เพื่อดึงข้อมูล/ข้อมูลจากหน่วยความจำโดยใช้ร้านค้าเวกเตอร์ ร้านค้าเวกเตอร์สามารถใช้เพื่อจัดเก็บและจัดการข้อมูลเพื่อดึงข้อมูลได้อย่างมีประสิทธิภาพตามพร้อมท์หรือแบบสอบถาม
หากต้องการเรียนรู้กระบวนการใช้ VectorStoreRetrieverMemory ใน LangChain เพียงทำตามคำแนะนำต่อไปนี้:
ขั้นตอนที่ 1: ติดตั้งโมดูล
เริ่มกระบวนการใช้ตัวดึงหน่วยความจำโดยการติดตั้ง LangChain โดยใช้คำสั่ง pip:
pip ติดตั้ง langchain
ติดตั้งโมดูล FAISS เพื่อรับข้อมูลโดยใช้การค้นหาความคล้ายคลึงทางความหมาย:
pip ติดตั้ง faiss-gpu 
ติดตั้งโมดูล chromadb สำหรับการใช้ฐานข้อมูล Chroma มันทำหน้าที่เป็นที่เก็บเวกเตอร์เพื่อสร้างหน่วยความจำสำหรับรีทรีฟเวอร์:
pip ติดตั้ง chromadb 
จำเป็นต้องติดตั้ง tiktoken โมดูลอื่นซึ่งสามารถใช้เพื่อสร้างโทเค็นโดยการแปลงข้อมูลเป็นชิ้นเล็ก ๆ :
pip ติดตั้ง tiktoken 
ติดตั้งโมดูล OpenAI เพื่อใช้ไลบรารีสำหรับการสร้าง LLM หรือแชทบอทโดยใช้สภาพแวดล้อม:
pip ติดตั้ง openai 
ตั้งค่าสภาพแวดล้อม บน Python IDE หรือโน้ตบุ๊กโดยใช้คีย์ API จากบัญชี OpenAI:
นำเข้า คุณนำเข้า รับผ่าน
คุณ . ประมาณ [ 'OPENAI_API_KEY' ] = รับผ่าน . รับผ่าน ( 'คีย์ OpenAI API:' )
ขั้นตอนที่ 2: นำเข้าไลบรารี
ขั้นตอนต่อไปคือการรับไลบรารีจากโมดูลเหล่านี้เพื่อใช้ตัวดึงหน่วยความจำใน LangChain:
จาก แลงเชน แจ้ง นำเข้า พรอมต์เทมเพลตจาก วันเวลา นำเข้า วันเวลา
จาก แลงเชน llms นำเข้า OpenAI
จาก แลงเชน การฝัง . เปิดใจ นำเข้า OpenAIEmbeddings
จาก แลงเชน ห่วงโซ่ นำเข้า การสนทนาห่วงโซ่
จาก แลงเชน หน่วยความจำ นำเข้า VectorStoreRetrieverหน่วยความจำ
ขั้นตอนที่ 3: การเริ่มต้น Vector Store
คู่มือนี้ใช้ฐานข้อมูล Chroma หลังจากนำเข้าไลบรารี FAISS เพื่อแยกข้อมูลโดยใช้คำสั่งอินพุต:
นำเข้า ไฟส์จาก แลงเชน หมอสโตร์ นำเข้า ใน MemoryDocstore
#importing ไลบรารีสำหรับกำหนดค่าฐานข้อมูลหรือร้านค้าเวกเตอร์
จาก แลงเชน ร้านเวกเตอร์ นำเข้า ไฟส์
#create การฝังและข้อความเพื่อจัดเก็บไว้ในร้านค้าเวกเตอร์
การฝัง_ขนาด = 1536
ดัชนี = ไฟส์ อินเด็กซ์แฟลตL2 ( การฝัง_ขนาด )
การฝัง_fn = OpenAIEmbeddings ( ) . embed_query
ร้านเวกเตอร์ = ไฟส์ ( การฝัง_fn , ดัชนี , ใน MemoryDocstore ( { } ) , { } )
ขั้นตอนที่ 4: การสร้างรีทรีฟเวอร์ที่ได้รับการสนับสนุนจาก Vector Store
สร้างหน่วยความจำเพื่อจัดเก็บข้อความล่าสุดในการสนทนาและรับบริบทของการแชท:
รีทรีฟเวอร์ = ร้านเวกเตอร์ as_retriever ( search_kwargs = คำสั่ง ( เค = 1 ) )หน่วยความจำ = VectorStoreRetrieverหน่วยความจำ ( รีทรีฟเวอร์ = รีทรีฟเวอร์ )
หน่วยความจำ. บันทึก_บริบท ( { 'ป้อนข้อมูล' : : 'ฉันชอบกินพิซซ่า' } , { 'เอาท์พุท' : : 'มหัศจรรย์' } )
หน่วยความจำ. บันทึก_บริบท ( { 'ป้อนข้อมูล' : : “ฉันเก่งฟุตบอล” } , { 'เอาท์พุท' : : 'ตกลง' } )
หน่วยความจำ. บันทึก_บริบท ( { 'ป้อนข้อมูล' : : “ฉันไม่ชอบการเมือง” } , { 'เอาท์พุท' : : 'แน่นอน' } )
ทดสอบหน่วยความจำของโมเดลโดยใช้อินพุตที่ผู้ใช้ให้มาพร้อมประวัติ:
พิมพ์ ( หน่วยความจำ. load_memory_variables ( { 'แจ้ง' : : 'ฉันควรดูกีฬาอะไร?' } ) [ 'ประวัติศาสตร์' ] ) 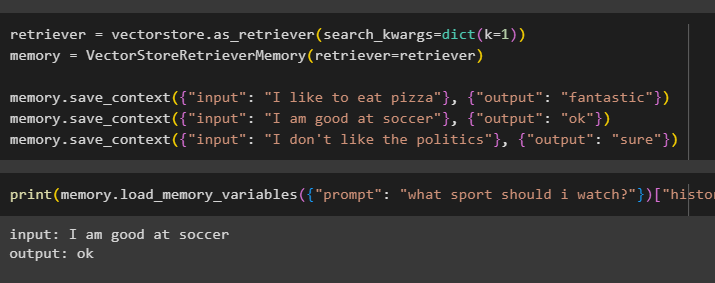
ขั้นตอนที่ 5: การใช้รีทรีฟเวอร์แบบโซ่
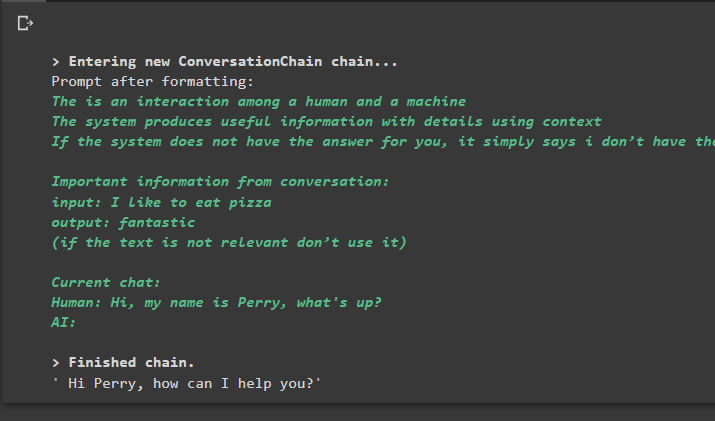
ขั้นตอนต่อไปคือการใช้รีทรีฟเวอร์หน่วยความจำกับเชนโดยการสร้าง LLM โดยใช้เมธอด OpenAI() และกำหนดค่าเทมเพลตพร้อมต์:
llm = OpenAI ( อุณหภูมิ = 0 )_DEFAULT_TEMPLATE = '''เป็นการปฏิสัมพันธ์ระหว่างมนุษย์กับเครื่องจักร
ระบบจัดทำข้อมูลที่เป็นประโยชน์พร้อมรายละเอียดตามบริบท
หากระบบไม่มีคำตอบสำหรับคุณ ระบบจะแจ้งว่าฉันไม่มีคำตอบ
ข้อมูลสำคัญจากการสนทนา:
{ประวัติศาสตร์}
(หากข้อความไม่เกี่ยวข้องอย่าใช้)
แชทปัจจุบัน:
มนุษย์: {อินพุต}
AI:'''
พร้อมท์ = พรอมต์เทมเพลต (
input_variables = [ 'ประวัติศาสตร์' , 'ป้อนข้อมูล' ] , แม่แบบ = _DEFAULT_TEMPLATE
)
#configure ConversationChain() โดยใช้ค่าสำหรับพารามิเตอร์
การสนทนา_กับ_สรุป = การสนทนาห่วงโซ่ (
llm = llm ,
พร้อมท์ = พร้อมท์ ,
หน่วยความจำ = หน่วยความจำ ,
รายละเอียด = จริง
)
การสนทนา_กับ_สรุป ทำนาย ( ป้อนข้อมูล = “สวัสดี ฉันชื่อเพอร์รี่ มีอะไรหรือเปล่า?” )
เอาท์พุต
การดำเนินการคำสั่งจะรันเชนและแสดงคำตอบที่ได้รับจากโมเดลหรือ LLM:
สนทนาต่อโดยใช้ข้อความแจ้งตามข้อมูลที่จัดเก็บไว้ในร้านค้าเวกเตอร์:
การสนทนา_กับ_สรุป ทำนาย ( ป้อนข้อมูล = 'กีฬาโปรดของฉันคืออะไร' ) 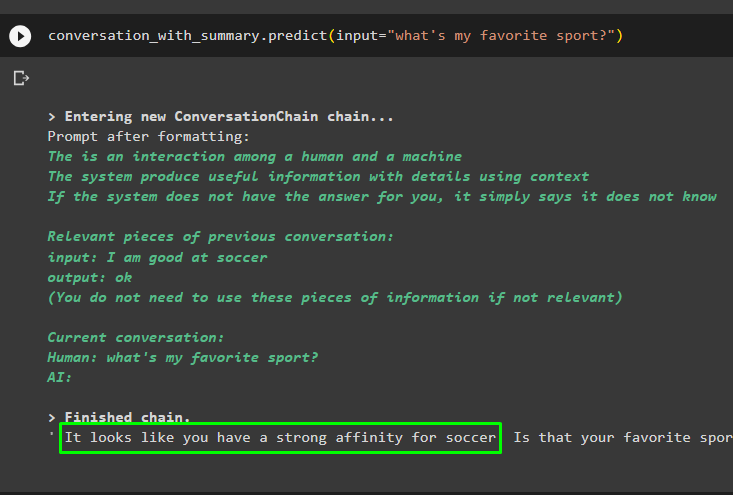
ข้อความก่อนหน้านี้จะถูกเก็บไว้ในหน่วยความจำของโมเดลซึ่งโมเดลสามารถใช้เพื่อทำความเข้าใจบริบทของข้อความ:
การสนทนา_กับ_สรุป ทำนาย ( ป้อนข้อมูล = “อาหารโปรดของฉันคืออะไร” ) 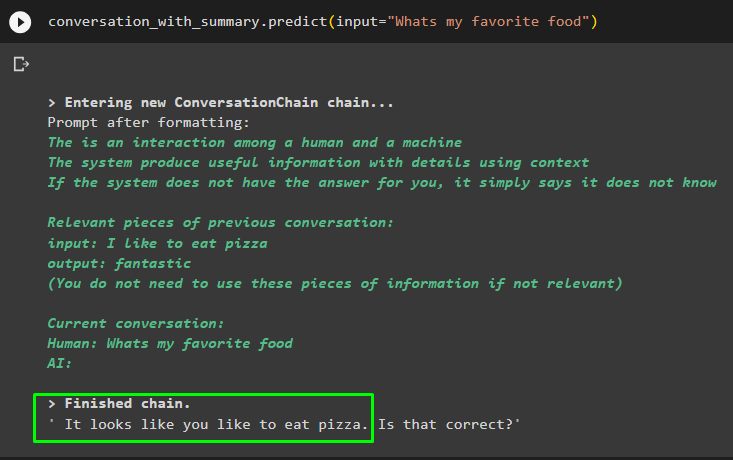
รับคำตอบที่ให้ไว้กับโมเดลในข้อความก่อนหน้านี้เพื่อตรวจสอบว่าตัวดึงข้อมูลหน่วยความจำทำงานอย่างไรกับโมเดลแชท:
การสนทนา_กับ_สรุป ทำนาย ( ป้อนข้อมูล = 'ฉันชื่ออะไร?' )โมเดลได้แสดงเอาต์พุตอย่างถูกต้องโดยใช้การค้นหาความคล้ายคลึงจากข้อมูลที่เก็บไว้ในหน่วยความจำ:
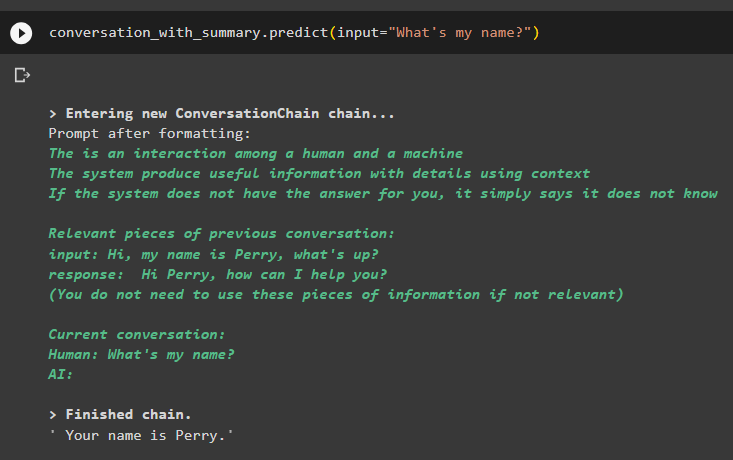
นั่นคือทั้งหมดที่เกี่ยวกับการใช้ vector storeดึงข้อมูลใน LangChain
บทสรุป
หากต้องการใช้ตัวดึงหน่วยความจำตามที่เก็บเวกเตอร์ใน LangChain เพียงติดตั้งโมดูลและเฟรมเวิร์กและตั้งค่าสภาพแวดล้อม หลังจากนั้น ให้นำเข้าไลบรารีจากโมดูลเพื่อสร้างฐานข้อมูลโดยใช้ Chroma จากนั้นตั้งค่าเทมเพลตพร้อมท์ ทดสอบรีทรีฟเวอร์หลังจากจัดเก็บข้อมูลในหน่วยความจำโดยเริ่มการสนทนาและถามคำถามที่เกี่ยวข้องกับข้อความก่อนหน้า คู่มือนี้ได้อธิบายรายละเอียดเกี่ยวกับกระบวนการใช้ไลบรารี VectorStoreRetrieverMemory ใน LangChain