สร้างคอลเลกชัน
ก่อนที่จะใช้ดัชนี เราต้องสร้างคอลเลกชันใหม่ใน MongoDB ของเรา เราได้สร้างไว้แล้วหนึ่งรายการและแทรกเอกสาร 10 รายการชื่อ 'Dummy' ฟังก์ชัน find() MongoDB จะแสดงบันทึกทั้งหมดจากคอลเลกชัน “Dummy” บนหน้าจอเชลล์ MongoDB ด้านล่าง
ทดสอบ> db.Dummy.find() 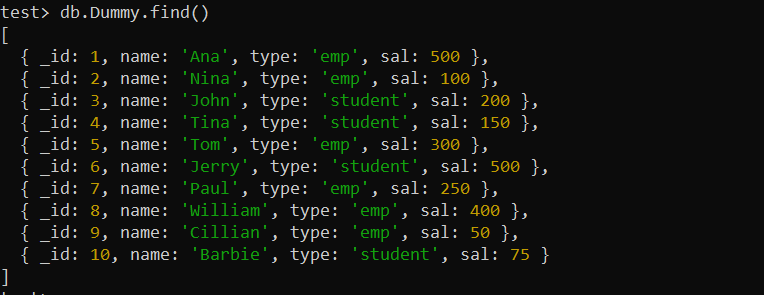
เลือกประเภทการจัดทำดัชนี
ก่อนที่จะสร้างดัชนี คุณต้องกำหนดคอลัมน์ที่จะใช้โดยทั่วไปในเกณฑ์การค้นหาก่อน ดัชนีทำงานได้ดีในคอลัมน์ที่มีการกรอง จัดเรียง หรือค้นหาบ่อยครั้ง ฟิลด์ที่มีจำนวนสมาชิกจำนวนมาก (ค่าที่แตกต่างกันจำนวนมาก) มักจะเป็นตัวเลือกการจัดทำดัชนีที่ดีเยี่ยม นี่คือตัวอย่างโค้ดบางส่วนสำหรับดัชนีประเภทต่างๆ
ตัวอย่างที่ 01: ดัชนีฟิลด์เดี่ยว
อาจเป็นดัชนีประเภทพื้นฐานที่สุด ซึ่งจัดทำดัชนีคอลัมน์เดียวเพื่อเพิ่มความเร็วในการสืบค้นในคอลัมน์นั้น ดัชนีประเภทนี้ใช้สำหรับการสืบค้นที่คุณใช้ฟิลด์คีย์เดียวในการสืบค้นบันทึกคอลเลกชัน สมมติว่าคุณใช้ฟิลด์ 'ประเภท' เพื่อสอบถามบันทึกของคอลเลกชัน 'Dummy' ภายในฟังก์ชันค้นหาดังต่อไปนี้ คำสั่งนี้จะตรวจสอบคอลเลกชันทั้งหมด ซึ่งอาจใช้เวลานานในการประมวลผลคอลเลกชันขนาดใหญ่ ดังนั้นเราจึงจำเป็นต้องปรับประสิทธิภาพของแบบสอบถามนี้ให้เหมาะสม
ทดสอบ> db.Dummy.find ({ประเภท: 'อีเอ็มป์' })
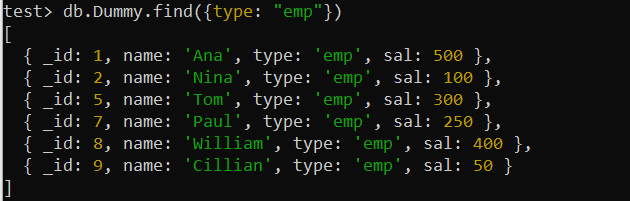
พบบันทึกของคอลเลกชัน Dummy ข้างต้นโดยใช้ฟิลด์ 'ประเภท' กล่าวคือ มีเงื่อนไข ดังนั้นจึงสามารถใช้ดัชนีคีย์เดียวที่นี่เพื่อเพิ่มประสิทธิภาพการค้นหา ดังนั้น เราจะใช้ฟังก์ชัน createIndex() ของ MongoDB เพื่อสร้างดัชนีบนฟิลด์ 'type' ของคอลเลกชัน 'Dummy' ภาพประกอบของการใช้เคียวรีนี้แสดงความสำเร็จในการสร้างดัชนีคีย์เดียวชื่อ 'type_1' บนเชลล์
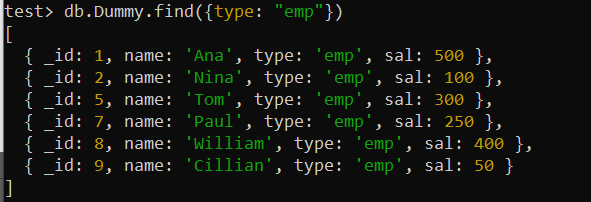
ทดสอบ> db.Dummy.createIndex ({ ประเภท: 1 })ลองใช้คำสั่ง find() เมื่อได้ประโยชน์จากการใช้ฟิลด์ 'type' ขณะนี้การดำเนินการจะเร็วกว่าฟังก์ชัน find() ที่ใช้ก่อนหน้านี้อย่างมากเนื่องจากมีดัชนีอยู่เนื่องจาก MongoDB สามารถใช้ดัชนีเพื่อดึงข้อมูลบันทึกที่มีตำแหน่งงานที่ร้องขอได้อย่างรวดเร็ว
ทดสอบ> db.Dummy.find ({ประเภท: 'อีเอ็มป์' })
ตัวอย่างที่ 02: ดัชนีแบบผสม
เราอาจต้องการค้นหารายการตามเกณฑ์ต่างๆ ในบางกรณี การใช้ดัชนีผสมสำหรับฟิลด์เหล่านี้สามารถช่วยปรับปรุงประสิทธิภาพคิวรีได้ สมมติว่าคราวนี้ คุณต้องการค้นหาจากคอลเลกชัน 'Dummy' โดยใช้ช่องหลายช่องที่มีเงื่อนไขการค้นหาที่แตกต่างกันตามที่แสดง แบบสอบถามนี้มีการค้นหาระเบียนจากคอลเลกชันที่ตั้งค่าฟิลด์ 'ประเภท' เป็น 'emp' และฟิลด์ 'sal' มากกว่า 350
ตัวดำเนินการเชิงตรรกะ $gte ถูกนำมาใช้เพื่อนำเงื่อนไขไปใช้กับช่อง 'sal' มีการส่งคืนเรกคอร์ดทั้งหมดสองเรกคอร์ดหลังจากค้นหาคอลเลกชันทั้งหมด ซึ่งประกอบด้วยเรกคอร์ด 10 รายการ
ทดสอบ> db.Dummy.find ({ประเภท: 'อีเอ็มป์' , ซัล: {$gte: 350 } }) 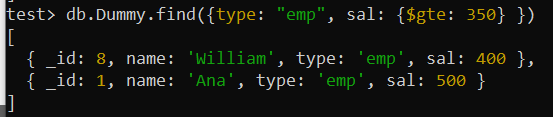
มาสร้างดัชนีแบบผสมสำหรับข้อความค้นหาข้างต้นกันดีกว่า ดัชนีผสมนี้มีฟิลด์ 'ประเภท' และ 'sal' ตัวเลข “1” และ “-1” แสดงถึงลำดับจากน้อยไปหามากและจากมากไปน้อยตามลำดับสำหรับช่อง “type” และ “sal” ลำดับของคอลัมน์ของดัชนีผสมมีความสำคัญและควรสอดคล้องกับรูปแบบการสืบค้น MongoDB ได้ตั้งชื่อ 'type_1_sal_-1' ให้กับดัชนีผสมนี้ตามที่แสดง
ทดสอบ> db.Dummy.createIndex ({ ประเภท: 1 , จะ:- 1 }) 
หลังจากใช้คำสั่ง find() เดียวกันเพื่อค้นหาบันทึกที่มีค่าฟิลด์ 'type' เป็น 'emp' และค่าของฟิลด์ 'sal' มากกว่าเท่ากับ 350 เราได้รับผลลัพธ์เดียวกันโดยมีการเปลี่ยนแปลงเล็กน้อยในลำดับ เทียบกับผลลัพธ์การสืบค้นครั้งก่อน ขณะนี้บันทึกค่าที่ใหญ่กว่าสำหรับฟิลด์ 'sal' อยู่ที่อันดับแรก ในขณะที่ค่าที่น้อยที่สุดจะอยู่ที่ต่ำสุดตามการตั้งค่า '-1' สำหรับฟิลด์ 'sal' ในดัชนีผสมด้านบน
ทดสอบ> db.Dummy.find ({ประเภท: 'อีเอ็มป์' , ซัล: {$gte: 350 } }) 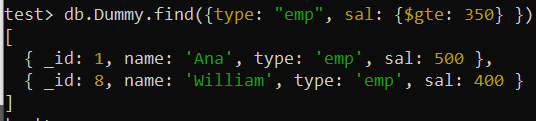
ตัวอย่าง 03: ดัชนีข้อความ
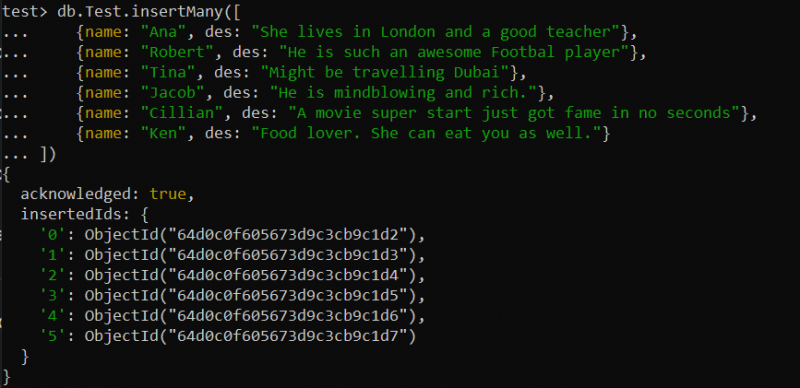
บางครั้ง คุณอาจเผชิญกับสถานการณ์ที่คุณควรจัดการกับชุดข้อมูลขนาดใหญ่ เช่น คำอธิบายผลิตภัณฑ์ขนาดใหญ่ ส่วนผสม ฯลฯ ดัชนีข้อความอาจมีประโยชน์สำหรับการค้นหาข้อความแบบเต็มในช่องข้อความขนาดใหญ่ ตัวอย่างเช่น เราได้สร้างคอลเลกชันใหม่ชื่อ 'ทดสอบ' ภายในฐานข้อมูลทดสอบของเรา แทรกทั้งหมด 6 ระเบียนในคอลเลกชันนี้โดยใช้ฟังก์ชัน insertMany() ตามแบบสอบถาม find() ด้านล่าง
ทดสอบ> db.Test.insertMany ([{ชื่อ: “อันนา” , ของ: “เธออาศัยอยู่ในลอนดอนและเป็นครูที่ดี” },
{ชื่อ: 'โรเบิร์ต' , ของ: “เขาเป็นนักฟุตบอลที่เก่งมาก” },
{ชื่อ: 'จาก' , ของ: “อาจจะไปเที่ยวดูไบ” },
{ชื่อ: “ยาโคบ” , ของ: “เขามีจิตใจที่น่าทึ่งและร่ำรวย” },
{ชื่อ: “ซิลเลียน” , ของ: 'ภาพยนตร์ที่เริ่มต้นอย่างยิ่งใหญ่เพิ่งจะโด่งดังในไม่กี่วินาที' },
{ชื่อ: 'เคน' , ของ: “คนรักอาหาร เธอก็กินคุณได้เช่นกัน” }
])
ตอนนี้ เราจะสร้างดัชนีข้อความในช่อง “Des” ของคอลเลกชันนี้ โดยใช้ฟังก์ชัน createIndex() ของ MongoDB คำหลัก “ข้อความ” ในค่าฟิลด์จะแสดงประเภทของดัชนี ซึ่งเป็นดัชนี “ข้อความ” ชื่อดัชนี des_text ได้รับการสร้างขึ้นโดยอัตโนมัติ
ทดสอบ> db.Test.createIndex ({ คำอธิบาย: 'ข้อความ' })ขณะนี้ฟังก์ชัน find() ได้ถูกนำมาใช้เพื่อดำเนินการ 'ค้นหาข้อความ' ในคอลเลกชันผ่านดัชนี 'des_text' ตัวดำเนินการ $search ถูกใช้เพื่อค้นหาคำว่า 'อาหาร' ในบันทึกการรวบรวมและแสดงบันทึกนั้น ๆ
ทดสอบ> db.Test.find({ $text: { $search: 'อาหาร' }}); 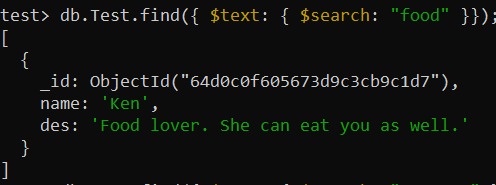
ตรวจสอบดัชนี:
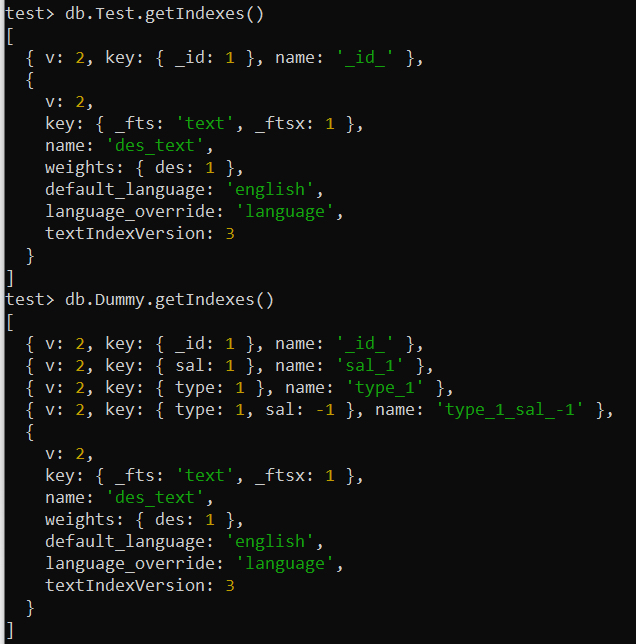
คุณสามารถตรวจสอบและแสดงรายการดัชนีที่ใช้ทั้งหมดของคอลเลกชันต่างๆ ใน MongoDB ของคุณได้ สำหรับสิ่งนี้ ให้ใช้เมธอด getIndexes() พร้อมกับชื่อของคอลเลกชันในหน้าจอเชลล์ MongoDB ของคุณ เราใช้คำสั่งนี้แยกกันสำหรับคอลเลกชัน 'Test' และ 'Dummy' นี่จะแสดงข้อมูลที่จำเป็นทั้งหมดเกี่ยวกับดัชนีในตัวและดัชนีที่ผู้ใช้กำหนดบนหน้าจอของคุณ
ทดสอบ> db.Test.getIndexes()ทดสอบ> db.Dummy.getIndexes()
วางดัชนี:
ถึงเวลาที่จะลบดัชนีที่สร้างขึ้นก่อนหน้านี้สำหรับคอลเลกชันโดยใช้ฟังก์ชัน dropIndex() พร้อมกับชื่อฟิลด์เดียวกันกับที่ใช้ดัชนี ข้อความค้นหาด้านล่างแสดงว่ามีการลบดัชนีเดียวแล้ว
ทดสอบ> db.Dummy.dropIndex ({ประเภท: 1 }) 
ในทำนองเดียวกัน ดัชนีผสมสามารถลดลงได้
ทดสอบ> ดัชนี db.Dummy.drop ({ประเภท: 1 , จะ: 1 }) 
บทสรุป
ด้วยการเร่งความเร็วในการดึงข้อมูลจาก MongoDB การจัดทำดัชนีจึงเป็นสิ่งจำเป็นสำหรับการเพิ่มประสิทธิภาพของการสืบค้น เมื่อไม่มีดัชนี MongoDB จะต้องค้นหาบันทึกที่ตรงกันในคอลเลกชันทั้งหมด ซึ่งจะมีประสิทธิภาพน้อยลงเมื่อขนาดของชุดเพิ่มขึ้น ความสามารถของ MongoDB ในการค้นหาบันทึกที่ถูกต้องอย่างรวดเร็วโดยใช้โครงสร้างฐานข้อมูลดัชนีจะเร่งการประมวลผลแบบสอบถามเมื่อใช้การจัดทำดัชนีที่เหมาะสม