ในบทความนี้ เราจะพูดถึงวิธีการจัดสรร แตกต่าง หน่วยความจำผ่านทาง “ pytorch_cuda_alloc_conf ' วิธี.
วิธี “pytorch_cuda_alloc_conf” ใน PyTorch คืออะไร
โดยพื้นฐานแล้ว “ pytorch_cuda_alloc_conf ” เป็นตัวแปรสภาพแวดล้อมภายในกรอบงาน PyTorch ตัวแปรนี้ช่วยให้สามารถจัดการทรัพยากรการประมวลผลที่มีอยู่ได้อย่างมีประสิทธิภาพ ซึ่งหมายความว่าแบบจำลองจะทำงานและให้ผลลัพธ์ในระยะเวลาน้อยที่สุดที่เป็นไปได้ หากไม่ทำอย่างถูกต้อง “ แตกต่าง ” แพลตฟอร์มการคำนวณจะแสดง “ ความจำเต็ม ” เกิดข้อผิดพลาดและส่งผลต่อรันไทม์ โมเดลที่ต้องฝึกอบรมกับข้อมูลปริมาณมากหรือมีข้อมูลขนาดใหญ่” ขนาดชุด ” อาจทำให้เกิดข้อผิดพลาดรันไทม์ได้เนื่องจากการตั้งค่าเริ่มต้นอาจไม่เพียงพอสำหรับข้อผิดพลาดเหล่านั้น
“ pytorch_cuda_alloc_conf ” ตัวแปรใช้สิ่งต่อไปนี้ “ ตัวเลือก ” เพื่อจัดการการจัดสรรทรัพยากร:
- พื้นเมือง : ตัวเลือกนี้ใช้การตั้งค่าที่มีอยู่แล้วใน PyTorch เพื่อจัดสรรหน่วยความจำให้กับโมเดลที่กำลังดำเนินการ
- max_split_size_mb : ช่วยให้มั่นใจได้ว่าบล็อกโค้ดใด ๆ ที่ใหญ่กว่าขนาดที่ระบุจะไม่ถูกแยกออก นี่เป็นเครื่องมือที่ทรงพลังในการป้องกัน” การกระจายตัว '. เราจะใช้ตัวเลือกนี้สำหรับการสาธิตในบทความนี้
- Roundup_power2_divisions : ตัวเลือกนี้จะปัดเศษขนาดของการจัดสรรให้ใกล้เคียงที่สุด “ ยกกำลัง 2 ” แบ่งเป็นเมกะไบต์ (MB)
- Roundup_bypass_threshold_mb: สามารถปัดเศษขนาดการจัดสรรสำหรับคำขอใด ๆ ที่แสดงรายการเกินเกณฑ์ที่ระบุ
- Garb_collection_threshold : ป้องกันความล่าช้าโดยการใช้หน่วยความจำที่มีอยู่จาก GPU แบบเรียลไทม์เพื่อให้แน่ใจว่าโปรโตคอลการเรียกคืนทั้งหมดไม่ได้เริ่มต้นขึ้น
จะจัดสรรหน่วยความจำโดยใช้วิธี 'pytorch_cuda_alloc_conf' ได้อย่างไร
โมเดลใดๆ ที่มีชุดข้อมูลขนาดใหญ่จำเป็นต้องมีการจัดสรรหน่วยความจำเพิ่มเติมที่มากกว่าที่ตั้งไว้ตามค่าเริ่มต้น จำเป็นต้องระบุการจัดสรรแบบกำหนดเองโดยคำนึงถึงข้อกำหนดของโมเดลและทรัพยากรฮาร์ดแวร์ที่มีอยู่
ทำตามขั้นตอนด้านล่างเพื่อใช้ ' pytorch_cuda_alloc_conf ” ใน Google Colab IDE เพื่อจัดสรรหน่วยความจำเพิ่มเติมให้กับโมเดลแมชชีนเลิร์นนิงที่ซับซ้อน:
ขั้นตอนที่ 1: เปิด Google Colab
ค้นหา Google การทำงานร่วมกัน ในเบราว์เซอร์และสร้าง ' โน๊ตบุ๊คใหม่ ” เพื่อเริ่มทำงาน:
ขั้นตอนที่ 2: ตั้งค่าโมเดล PyTorch แบบกำหนดเอง
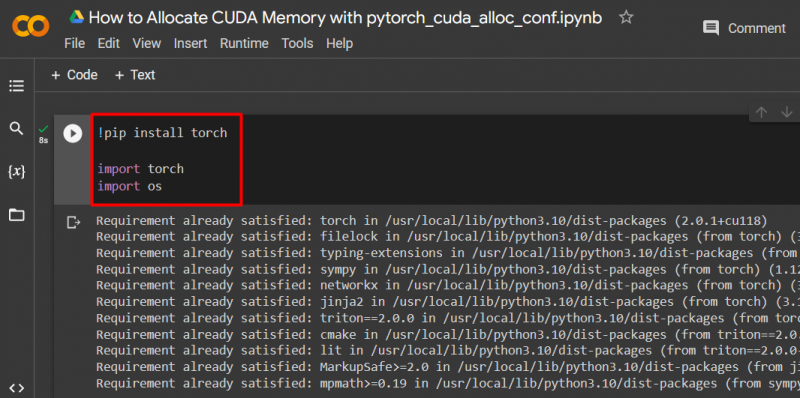
ตั้งค่าโมเดล PyTorch โดยใช้ปุ่ม “ !ปิ๊ป ” แพ็คเกจการติดตั้งเพื่อติดตั้ง “ คบเพลิง ” ห้องสมุด และ “ นำเข้า ” คำสั่งนำเข้า “ คบเพลิง ' และ ' คุณ ” ไลบรารี่ในโครงการ:
นำเข้าไฟฉาย
นำเข้าเรา
จำเป็นต้องมีไลบรารีต่อไปนี้สำหรับโปรเจ็กต์นี้:
- คบเพลิง – นี่คือไลบรารีพื้นฐานที่ใช้ PyTorch
- คุณ – “ ระบบปฏิบัติการ ” ไลบรารี่ใช้เพื่อจัดการงานที่เกี่ยวข้องกับตัวแปรสภาพแวดล้อมเช่น “ pytorch_cuda_alloc_conf ” รวมถึงไดเร็กทอรีระบบและการอนุญาตไฟล์:
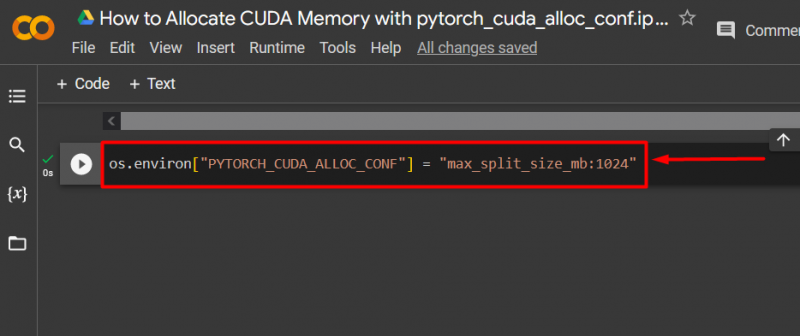
ขั้นตอนที่ 3: จัดสรรหน่วยความจำ CUDA
ใช้ ' pytorch_cuda_alloc_conf ” วิธีการระบุขนาดการแยกสูงสุดโดยใช้ “ max_split_size_mb ”:
ขั้นตอนที่ 4: ดำเนินโครงการ PyTorch ของคุณต่อ
หลังจากระบุ “ แตกต่าง ” การจัดสรรพื้นที่ด้วย “ max_split_size_mb ” ให้ทำงานต่อในโครงการ PyTorch ตามปกติโดยไม่ต้องกลัวว่า “ ความจำเต็ม ' ข้อผิดพลาด.
บันทึก : คุณสามารถเข้าถึงสมุดบันทึก Google Colab ของเราได้ที่นี้ ลิงค์ .
โปรทิป
ดังที่ได้กล่าวไปแล้วว่า “ pytorch_cuda_alloc_conf ” สามารถใช้ตัวเลือกที่ให้ไว้ข้างต้นได้ ใช้สิ่งเหล่านี้ตามความต้องการเฉพาะของโปรเจ็กต์การเรียนรู้เชิงลึกของคุณ
ความสำเร็จ! เราเพิ่งสาธิตวิธีการใช้ “ pytorch_cuda_alloc_conf ” วิธีการระบุ “ max_split_size_mb ” สำหรับโครงการ PyTorch
บทสรุป
ใช้ ' pytorch_cuda_alloc_conf ” วิธีการจัดสรรหน่วยความจำ CUDA โดยใช้ตัวเลือกใดตัวเลือกหนึ่งที่มีอยู่ตามความต้องการของรุ่น ตัวเลือกเหล่านี้แต่ละตัวเลือกมีไว้เพื่อบรรเทาปัญหาการประมวลผลเฉพาะภายในโปรเจ็กต์ PyTorch เพื่อรันไทม์ที่ดีขึ้นและการดำเนินงานที่ราบรื่นยิ่งขึ้น ในบทความนี้ เราได้แสดงไวยากรณ์เพื่อใช้เครื่องหมาย “ max_split_size_mb ” เพื่อกำหนดขนาดสูงสุดของการแยก