เมธอด “Series.to_csv()” ใน Pandas จะแสดงออบเจ็กต์ชุดข้อมูลที่ระบุในรูปแบบค่าที่คั่นด้วยเครื่องหมายจุลภาค (csv) ฟังก์ชันนี้ใช้ค่าจากชุดข้อมูลและแก้ไขรูปแบบโดยใส่เครื่องหมายจุลภาคเพื่อแยกค่าดัชนีและคอลัมน์
ในการใช้ฟังก์ชันนี้ เราต้องใช้ไวยากรณ์ต่อไปนี้:

บทความนี้จะให้เทคนิคสองแบบที่แตกต่างกันแก่คุณเพื่อเรียนรู้วิธีการใช้งานวิธีนี้ในโปรแกรมหลาม
ตัวอย่าง # 1: การใช้ Series.to_csv() วิธีการแปลงชุดข้อมูลด้วย DatetimeIndex เป็นค่าที่คั่นด้วยจุลภาค
ในการแก้ไขซีรีส์ให้อยู่ในรูปแบบ CSV เราจะใช้ฟังก์ชัน “Series.to_csv()” ภาพประกอบนี้จะสร้างชุดข้อมูลที่มี DatetimeIndex แล้วแปลงเป็นรูปแบบค่าที่คั่นด้วยเครื่องหมายจุลภาค
สำหรับการนำวิธีนี้ไปใช้ เราต้องมีเครื่องมือที่รองรับการเขียนโปรแกรมหลาม เครื่องมือ “Spyder” ใช้สำหรับรวบรวมรหัส ในการเขียนสคริปต์นั้น ก่อนอื่นเราได้เปิดตัวเครื่องมือที่ติดตั้งในระบบของเรา โปรแกรม python ต้องการห้องสมุดเพื่อใช้วิธีการเพื่อให้บรรลุผลลัพธ์ที่ต้องการ ห้องสมุดที่เราโหลดไว้ที่นี่คือ “แพนด้า” ในโค้ดบรรทัดเดียวกัน นามแฝงของไลบรารีนี้ถูกระบุว่าเป็น “pd” ดังนั้น ไม่ว่าในโปรแกรมใด เราต้องเขียน 'แพนด้า' เพื่อเข้าถึงฟังก์ชัน เราจะเขียน 'pd' แทน
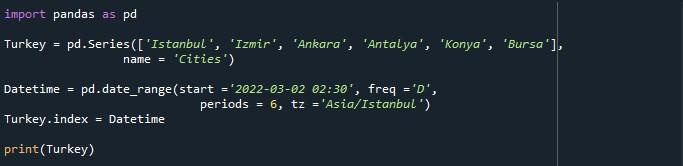
ขั้นตอนแรกในการเริ่มต้นด้วยโค้ดคือการสร้างชุด Pandas เราต้องเขียน “pd” เพื่อใช้วิธีสร้างซีรีส์จากแพนด้า ฟังก์ชัน “pd.Series()” ถูกเรียกให้สร้างชุดข้อมูลด้วยค่าที่ระบุ ค่าที่เราให้ไว้สำหรับซีรีส์คือ 'อิสตันบูล', 'อิซเมียร์', 'อังการา', 'อังการา', 'อันตัลยา', 'คอนยา' และ 'บูร์ซา' หากคุณต้องการตั้งชื่อให้กับอาร์เรย์ของค่านี้ คุณสามารถทำได้โดยใช้พารามิเตอร์ 'name' ในที่นี้ เราได้ตั้งชื่ออาร์เรย์ของค่านี้ว่า 'เมือง' เนื่องจากเป็นชื่อเมือง 6 เมือง ในการจัดเก็บชุดนี้ มีการสร้างวัตถุชุด 'ตุรกี'
ในการสร้าง DatetimeIndex เราได้เรียกใช้เมธอด “pd.date_range()” ระหว่างวงเล็บของฟังก์ชันนี้ เราได้ส่งอาร์กิวเมนต์ 4 รายการ ได้แก่ 'start', 'freq', 'periods' และ 'tz'
อาร์กิวเมนต์ 'start' ใช้วันที่และเวลาเพื่อเริ่มสร้างช่วงวันที่จากนั้น โดยได้กำหนดวันเวลาเริ่มต้นไว้เป็น “2022-03-02 02:30” พารามิเตอร์ 'ความถี่' กำลังจัดประเภทความถี่สำหรับช่วงวันที่ ดังนั้นเราจึงให้ค่า 'D' ตอนนี้จะสร้างช่วงวันที่ตามความถี่รายวัน อาร์กิวเมนต์ 'รอบระยะเวลา' ถูกตั้งค่าเป็น '6' ซึ่งหมายความว่าจะสร้างช่วงวันที่เป็นเวลา 6 วัน พารามิเตอร์สุดท้ายคือ 'tz' ซึ่งระบุเขตเวลาสำหรับพื้นที่ที่ระบุ เราได้ระบุโซนเวลาสำหรับ “เอเชีย/อิสตันบูล”
ในการจัดเก็บช่วงวันที่นี้ เราได้สร้างตัวแปร 'วันที่และเวลา' ในการตั้งค่า DatetimeIndex เราได้ใช้คุณสมบัติ “Series.index” ชื่อของซีรีส์ 'ตุรกี' มาพร้อมกับคุณสมบัติ '.index' และกำหนดช่วงวันที่ที่จัดเก็บไว้ในตัวแปร 'Datetime' ให้กับซีรีส์ ดังนั้นคุณสมบัติ 'ดัชนี' จะนำค่าจากตัวแปร 'วันที่และเวลา' มาเป็นรายการดัชนีของชุด 'ตุรกี' สุดท้าย เพื่อดูชุดผลลัพธ์ เราได้ใช้วิธี 'print()' และส่งชุดข้อมูล 'ตุรกี' เป็นอินพุตเพื่อแสดงเนื้อหา
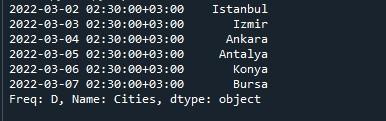
เราเพิ่งกดตัวเลือก 'เรียกใช้ไฟล์' เพื่อรันสคริปต์ ดังนั้นเราจึงสามารถดูซีรีส์ที่มี DatetimeIndex ได้ตั้งแต่ “2022-03-02 02:30:00+03:00” และสิ้นสุดที่ “2022-03-07 02:30:00+03:00″ สร้างช่วงเวลา จาก 6 วัน ด้านล่างชุดข้อมูล 'Freq :D' จะกล่าวถึงชื่อรายการอาร์เรย์ 'Cities' และ dtype 'object' ด้วย
ตอนนี้ เราจะเรียนรู้การแปลงชุดนี้ ซึ่งเราเพิ่งเห็นในสแนปชอตด้านบนเป็นรูปแบบ CSV ในการแก้ไขชุดข้อมูลให้เป็นค่าที่คั่นด้วยเครื่องหมายจุลภาค เรามีวิธีที่ให้โดยโมดูล pandas ซึ่งก็คือ “Series.to_csv()” วิธีนี้ใช้ค่าของชุดข้อมูลที่ระบุและเพิ่มเครื่องหมายจุลภาคระหว่างค่าของคอลัมน์
ฟังก์ชัน “Series.to_csv()” ถูกเรียก ชื่อของซีรีส์ที่เราต้องการแปลงนั้นถูกกล่าวถึงด้วยเมธอดว่า “Turkey.to_csv()” เพื่อรักษาค่าที่คั่นด้วยเครื่องหมายจุลภาค เราได้สร้างตัวแปร 'Comma_Separated' แล้วใส่เนื้อหาลงในหน้าต่างผลลัพธ์โดยเรียกใช้ฟังก์ชัน 'print()'

นี่คือซีรีส์ของเราในรูปแบบ csv เราจะเห็นได้ในสแน็ปช็อตว่าค่าดัชนีและชุดข้อมูลแยกจากกันโดยใช้เครื่องหมายจุลภาค

ตัวอย่าง # 2: การใช้เมธอด Series.to_csv() เพื่อแปลงซีรีส์ด้วยค่า NaN เป็นค่าที่คั่นด้วยเครื่องหมายจุลภาค
เทคนิคที่สองในการใช้วิธีการ “Series.to_csv()” คือการใช้วิธีนี้เพื่อแปลงชุดข้อมูลที่มีรายการว่างบางรายการให้อยู่ในรูปแบบ CSV
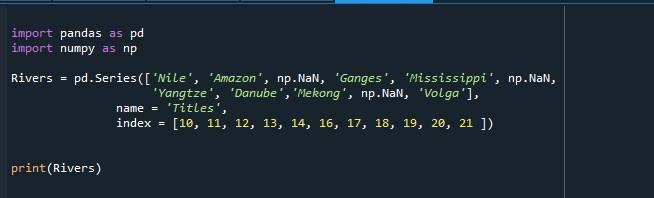
ในขั้นต้นเราได้นำเข้าแพ็คเกจที่จำเป็น “pd” ถูกสร้างเป็นนามแฝงสำหรับแพนด้าและ “np” เป็นนามแฝงสำหรับ numpy โหลดชุดเครื่องมือ numpy ที่นี่เพราะเราจะสร้างรายการว่างในซีรีส์ของเราโดยใช้ 'np.NaN' ในขณะที่สร้างโดยใช้วิธี 'pd.Series ()' ของแพนด้า
ฟังก์ชัน “pd.Series()” ถูกเรียกใช้สำหรับการสร้างซีรีส์แพนด้าด้วยค่าเหล่านี้: “Nile”, “Amazon”, np.NaN, “Ganges”, “Mississippi”, “np.NaN”, “Yangtze”, “แม่น้ำดานูบ”, “แม่น้ำโขง”, “นพ.น่าน” และ “โวลก้า” มีการกำหนดค่าทั้งหมด 21 ค่าสำหรับชุดข้อมูล โดย 3 รายการมีค่า 'np.NaN' ซึ่งหมายความว่าไม่มี 3 ค่าในชุดข้อมูล คุณสมบัติ 'ชื่อ' คือการระบุชื่อสำหรับอาร์เรย์ของค่าที่เราให้ไว้ 'ชื่อ' คุณสมบัติ 'ดัชนี' ใช้เพื่อตั้งค่ารายการดัชนีที่ผู้ใช้กำหนด แทนที่จะไปกับรายการเริ่มต้น
ที่นี่เราต้องการรายการดัชนีที่มีค่า '10', '11', '12', '13', '14', '16', '17', '18', '19', '20', และ 21” ตอนนี้ ซีรีส์ของเราจะมีรายการดัชนีเริ่มต้นจาก “10” แทนที่จะเป็น “0” ตอนนี้เก็บชุดนี้ไว้เพื่อใช้ในภายหลังในโปรแกรม เราได้เริ่มต้นอ็อบเจ็กต์ชุดข้อมูล 'Rivers' และจัดสรรอนุกรมเอาต์พุตที่สร้างขึ้นจากการเรียกเมธอด 'pd.Series()' ซีรีส์นี้สามารถมองเห็นได้โดยการแสดงโดยใช้ฟังก์ชัน “print()” โดย python
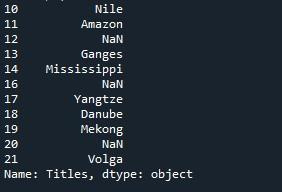
เอาต์พุตที่แสดงบนเทอร์มินัลพิมพ์ชุดรายการดัชนีเริ่มต้นจาก 10 และสิ้นสุดที่ 21 ซึ่งหมายความว่าชุดข้อมูลมีค่า 21 ค่า
ซีรีส์จะถูกแปลงเป็นรูปแบบ CSV ด้วยเมธอด “Series.to_csv()”
เราได้เรียกใช้เมธอด “Series.to_csv()” ด้วยชุด “Turkey” ของเรา ดังนั้น วิธีนี้จะใช้ค่าจากชุดข้อมูล 'ตุรกี' และแปลงเป็นรูปแบบค่าที่คั่นด้วยเครื่องหมายจุลภาค ผลลัพธ์จะถูกบันทึกไว้ในตัวแปร “Converted_csv” และในท้ายที่สุด ซีรีส์ที่แปลงแล้วจะถูกพิมพ์โดยใช้ฟังก์ชัน “print()”

ในภาพรวมของผลลัพธ์ด้านล่าง คุณจะเห็นว่าค่าของชุดข้อมูลมีการเปลี่ยนแปลงในลักษณะที่ใช้เครื่องหมายจุลภาคเพื่อแยกค่าเหล่านี้ออกจากรายการดัชนี นอกจากนี้ ในกรณีที่ไม่มีค่า เฉพาะหมายเลขดัชนีเท่านั้นที่พิมพ์ด้วยเครื่องหมายจุลภาค

บทสรุป
การปรับเปลี่ยนซีรีส์แพนด้าเป็นรูปแบบ CSV เป็นแนวทางที่ใช้งานได้จริง สามารถทำได้โดยใช้ฟังก์ชัน 'Series.to_csv()' ของแพนด้า คู่มือนี้นำเทคนิคสองวิธีมาใช้ในการปฏิบัติ ในภาพประกอบแรก เราได้เรียกใช้วิธีนี้เพื่อแปลงชุดข้อมูลด้วย DatetimeIndex เป็นรูปแบบค่าที่คั่นด้วยเครื่องหมายจุลภาค อินสแตนซ์ที่ 2 ใช้ฟังก์ชัน “Series.to_csv()” เพื่อแก้ไขซีรีส์ที่มีรายการที่ขาดหายไปบางส่วนในรูปแบบ CSV เทคนิคทั้งสองนี้ถูกนำไปใช้จริงโดยใช้เครื่องมือ “Spyder” บนระบบปฏิบัติการ Windows