บทความนี้จะกล่าวถึงวิธีใช้ Elasticsearch multi-get API เพื่อดึงเอกสาร JSON หลายรายการตาม ID ของพวกเขา นอกจากนี้ Elasticsearch ยังให้คุณใช้การสืบค้นข้อมูลเดียวเพื่อดึงเอกสารจากดัชนีโดยใช้ ID เอกสารเท่านั้น
มาสำรวจกัน
ขอไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์สำหรับ Elasticsearch multi-get API:
GET /_mget
GET /
Multi-get API รองรับดัชนีหลายตัวที่ให้คุณดึงเอกสารได้ แม้ว่าจะไม่ได้อยู่ในดัชนีเดียวกันก็ตาม
คำขอรองรับพารามิเตอร์เส้นทางต่อไปนี้:
-
– ชื่อของดัชนีที่จะดึงเอกสารตามที่ระบุโดย ID ของพวกเขา
คุณยังสามารถระบุพารามิเตอร์การสืบค้นอื่นๆ ตามที่แสดง:
- ความพึงใจ – กำหนดโหนดหรือชาร์ดที่ต้องการ
- เรียลไทม์ – หากตั้งค่าเป็น จริง การดำเนินการจะดำเนินการตามเวลาจริง
- รีเฟรช – บังคับให้การดำเนินการรีเฟรชชาร์ดเป้าหมายก่อนที่จะดึงเอกสารที่ระบุ
- การกำหนดเส้นทาง – ค่าที่ใช้ในการกำหนดเส้นทางการดำเนินการไปยังชาร์ดเฉพาะ
- Store_fields – ดึงฟิลด์เอกสารที่เก็บไว้ในดัชนีแทนที่จะเป็นเอกสาร
- _แหล่งที่มา – ค่าบูลีนที่กำหนดว่าคำขอควรส่งคืนฟิลด์ _source หรือไม่
แบบสอบถามต้องการเนื้อหา ซึ่งรวมถึงค่าต่อไปนี้:
- เอกสาร – ระบุเอกสารที่คุณต้องการดึง นอกจากนี้ ส่วนนี้สนับสนุนแอตทริบิวต์ต่อไปนี้:
- _id – ID เฉพาะของเอกสารเป้าหมาย
- _ดัชนี – ดัชนีที่มีเอกสารเป้าหมาย
- การกำหนดเส้นทาง – คีย์สำหรับชาร์ดหลักของเอกสาร
- _แหล่งที่มา – ถ้าเป็นจริง จะรวมฟิลด์ต้นทางทั้งหมด มิฉะนั้นจะไม่รวมพวกเขา
- _stored_fields –store_fields ที่คุณต้องการรวม
- รหัส – รหัสของเอกสารที่คุณต้องการดึง
ตัวอย่างที่ 1: ดึงเอกสารหลายฉบับจากดัชนีเดียวกัน
ตัวอย่างต่อไปนี้แสดงวิธีใช้ Elasticsearch multi-get API เพื่อดึงเอกสารที่มี ID เฉพาะจากดัชนี Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: การรายงาน' -H 'ประเภทเนื้อหา: แอปพลิเคชัน/json' -d'{
'เอกสาร': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
คำขอที่ได้รับควรดึงเอกสารที่มี ID ที่ระบุจากดัชนี Netflix ผลลัพธ์ที่ได้จะเป็นดังที่แสดง:
{'เอกสาร': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_รุ่น': 1,
'_seq_no': 0
'_primary_term': 1,
'พบ': จริง
'_แหล่งที่มา': {
'duration': '90 นาที',
'listed_in': 'สารคดี',
'ประเทศ': 'สหรัฐอเมริกา',
'date_added': '25 กันยายน 2564',
'show_id': 's1',
'ผู้กำกับ': 'เคิร์สเทน จอห์นสัน',
'release_year': 2020,
'เรตติ้ง': 'PG-13',
'description': 'ในขณะที่พ่อของเธอใกล้จะถึงจุดจบของชีวิต ผู้สร้างภาพยนตร์ Kirsten Johnson ได้แสดงความตายของเขาด้วยวิธีที่สร้างสรรค์และตลกขบขันเพื่อช่วยให้ทั้งคู่เผชิญกับสิ่งที่หลีกเลี่ยงไม่ได้',
'type': 'ภาพยนตร์',
'title': 'Dick Johnson Is Dead'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_รุ่น': 1,
'_seq_no': 12,
'_primary_term': 1,
'พบ': จริง
'_แหล่งที่มา': {
'country': 'เยอรมนี, สาธารณรัฐเช็ก',
'show_id': 's13',
'ผู้กำกับ': 'คริสเตียน ชโวเคอว์',
'release_year': 2021,
'เรตติ้ง': 'TV-MA',
'description': 'หลังจากที่ครอบครัวของเธอส่วนใหญ่ถูกสังหารในเหตุระเบิดของผู้ก่อการร้าย หญิงสาวคนหนึ่งถูกล่อให้เข้าร่วมกลุ่มที่ฆ่าพวกเขาโดยไม่รู้ตัว',
'type': 'ภาพยนตร์',
'title': 'ฉันคือคาร์ล',
'duration': '127 นาที',
'listed_in': 'ละคร ภาพยนตร์ต่างประเทศ',
'นักแสดง': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23 กันยายน 2021'
}
}
]
}
นอกจากนี้เรายังสามารถทำให้คำของ่ายขึ้นโดยใส่ ID เอกสารในอาร์เรย์อย่างง่ายดังที่แสดงต่อไปนี้:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: การรายงาน' -H 'ประเภทเนื้อหา: แอปพลิเคชัน/json' -d'{
'รหัส': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
คำขอก่อนหน้านี้ควรดำเนินการในลักษณะเดียวกัน
ตัวอย่างที่ 2: ดึงเอกสารจากหลายดัชนี
ในตัวอย่างต่อไปนี้ คำขอดึงเอกสารหลายฉบับจากดัชนีต่างๆ ดังที่แสดง:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: การรายงาน' -H 'ประเภทเนื้อหา: แอปพลิเคชัน/json' -d'{
'เอกสาร': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'ดิสนีย์',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
ผลลัพธ์ที่ได้จะเป็นดังภาพ:

ตัวอย่างที่ 3: ยกเว้นฟิลด์เฉพาะ
เราสามารถแยกฟิลด์เฉพาะออกจากคำขอที่กำหนดโดยใช้พารามิเตอร์ source_include และ source_exclude
ตัวอย่างเป็นที่แสดง:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: การรายงาน' -H 'ประเภทเนื้อหา: แอปพลิเคชัน/json' -d'{
'เอกสาร': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': เท็จ
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_แหล่งที่มา': {
'รวม': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'description', 'type', 'date_added' ]
}
}
]
}'
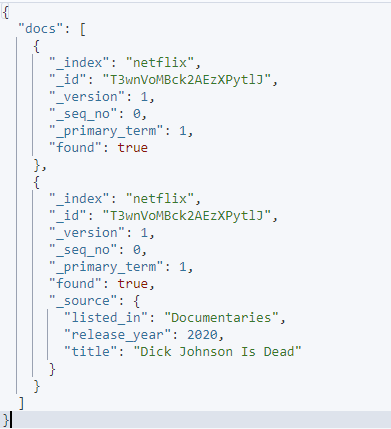
คำขอที่ให้มานั้นใช้แหล่งที่มาที่รวมและไม่รวมเพื่อระบุฟิลด์ที่คุณต้องการดึงข้อมูลในเอกสารที่กำหนด
ผลลัพธ์ที่ได้จะเป็นดังภาพ:
บทสรุป
ในโพสต์นี้ เราได้พูดถึงพื้นฐานของการทำงานกับ Elasticsearch multi-get API ซึ่งช่วยให้คุณดึงเอกสารหลายฉบับจากแหล่งต่างๆ ตาม ID ของพวกเขา อย่าลังเลที่จะสำรวจเอกสารอื่น ๆ สำหรับข้อมูลเพิ่มเติม
มีความสุขในการเข้ารหัส!