ปัญญาประดิษฐ์เป็นหนึ่งในเทคโนโลยีที่เติบโตอย่างรวดเร็วที่สุดโดยใช้อัลกอริธึมการเรียนรู้ของเครื่องเพื่อฝึกฝนและทดสอบแบบจำลองโดยใช้ข้อมูลขนาดใหญ่ ข้อมูลสามารถจัดเก็บในรูปแบบที่แตกต่างกันได้ แต่ในการสร้างโมเดลภาษาขนาดใหญ่โดยใช้ LangChain ประเภทที่ใช้มากที่สุดคือ JSON ข้อมูลการฝึกอบรมและการทดสอบจะต้องมีความชัดเจนและครบถ้วนโดยไม่มีความคลุมเครือใดๆ เพื่อให้แบบจำลองสามารถทำงานได้อย่างมีประสิทธิภาพ
คู่มือนี้จะสาธิตกระบวนการใช้ JSON parser pydantic ใน LangChain
จะใช้ Parser Pydantic (JSON) ใน LangChain ได้อย่างไร
ข้อมูล JSON มีรูปแบบข้อความของข้อมูลที่สามารถรวบรวมได้ผ่านการคัดลอกเว็บและแหล่งที่มาอื่นๆ เช่น บันทึก ฯลฯ เพื่อตรวจสอบความถูกต้องของข้อมูล LangChain ใช้ไลบรารี pydantic จาก Python เพื่อทำให้กระบวนการง่ายขึ้น หากต้องการใช้ JSON parser pydantic ใน LangChain เพียงอ่านคู่มือนี้:
ขั้นตอนที่ 1: ติดตั้งโมดูล
เพื่อเริ่มต้นกระบวนการ เพียงติดตั้งโมดูล LangChain เพื่อใช้ไลบรารีสำหรับการใช้ parser ใน LangChain:
ปิ๊ป ติดตั้ง แลงเชน
ตอนนี้ใช้ ' การติดตั้ง pip ” เพื่อรับกรอบ OpenAI และใช้ทรัพยากร:
ปิ๊ป ติดตั้ง เปิดใจ
หลังจากติดตั้งโมดูล เพียงเชื่อมต่อกับสภาพแวดล้อม OpenAI โดยระบุคีย์ API โดยใช้เครื่องหมาย “ คุณ ' และ ' รับผ่าน ” ห้องสมุด:
นำเข้าเรานำเข้า getpass
ระบบปฏิบัติการ.สภาพแวดล้อม [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'คีย์ OpenAI API:' )

ขั้นตอนที่ 2: นำเข้าไลบรารี
ใช้โมดูล LangChain เพื่อนำเข้าไลบรารีที่จำเป็นซึ่งสามารถใช้ในการสร้างเทมเพลตสำหรับพรอมต์ เทมเพลตสำหรับพรอมต์อธิบายวิธีการถามคำถามในภาษาธรรมชาติ เพื่อให้โมเดลสามารถเข้าใจพรอมต์ได้อย่างมีประสิทธิภาพ นอกจากนี้ ให้นำเข้าไลบรารี เช่น OpenAI และ ChatOpenAI เพื่อสร้างเครือข่ายโดยใช้ LLM เพื่อสร้างแชทบอต:
จากการนำเข้า langchain.prompts (พรอมต์เทมเพลต,
เทมเพลต ChatPrompt,
เทมเพลต HumanMessagePrompt,
)
จาก langchain.llms นำเข้า OpenAI
จาก langchain.chat_models นำเข้า ChatOpenAI
หลังจากนั้น ให้นำเข้าไลบรารี pydantic เช่น BaseModel, Field และ validator เพื่อใช้ JSON parser ใน LangChain:
จาก langchain.output_parsers นำเข้า PydanticOutputParserจากการนำเข้า pydantic BaseModel, Field, validator
จากการพิมพ์รายการนำเข้า
ขั้นตอนที่ 3: การสร้างแบบจำลอง
หลังจากได้รับไลบรารีทั้งหมดสำหรับการใช้ pydantic JSON parser แล้ว เพียงรับโมเดลทดสอบที่ออกแบบไว้ล่วงหน้าด้วยวิธี OpenAI():
model_name= 'ข้อความ-ดาวินชี-003'อุณหภูมิ = 0.0
รุ่น = OpenAI ( รุ่น_ชื่อ =ชื่อรุ่น, อุณหภูมิ =อุณหภูมิ )
ขั้นตอนที่ 4: กำหนดค่า Actor BaseModel
สร้างแบบจำลองอื่นเพื่อหาคำตอบที่เกี่ยวข้องกับนักแสดง เช่น ชื่อและภาพยนตร์ โดยถามถึงผลงานภาพยนตร์ของนักแสดง:
นักแสดงคลาส ( BaseModel ) : :ชื่อ: str = สนาม ( คำอธิบาย = “ชื่อนักแสดงนำ” )
film_names: รายการ [ STR ] = สนาม ( คำอธิบาย = 'ภาพยนตร์ที่นักแสดงนำ' )
Actor_query = “ฉันอยากเห็นผลงานของนักแสดงคนไหน”
ตัวแยกวิเคราะห์ = PydanticOutputParser ( pydantic_object =นักแสดง )
prompt = พร้อมต์เทมเพลต (
แม่แบบ = 'ตอบกลับข้อความแจ้งจากผู้ใช้ \n {format_instructions} \n {แบบสอบถาม} \n ' ,
input_variables = [ 'สอบถาม' ] ,
ตัวแปรบางส่วน = { 'รูปแบบ_คำแนะนำ' : parser.get_format_instructions ( ) } ,
)
ขั้นตอนที่ 5: ทดสอบโมเดลพื้นฐาน
เพียงรับเอาต์พุตโดยใช้ฟังก์ชัน parse() พร้อมด้วยตัวแปรเอาต์พุตที่มีผลลัพธ์ที่สร้างขึ้นสำหรับพรอมต์:
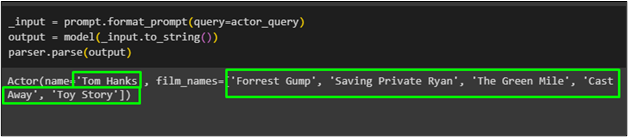
_input = prompt.format_prompt ( แบบสอบถาม =actor_query )เอาท์พุท = รุ่น ( _input.to_string ( ) )
parser.แยกวิเคราะห์ ( เอาท์พุท )
นักแสดงชื่อ “ ทอม แฮงค์ส ” โดยมีรายชื่อภาพยนตร์ของเขาถูกดึงมาโดยใช้ฟังก์ชัน pydantic จากแบบจำลอง:
นั่นคือทั้งหมดที่เกี่ยวกับการใช้ JSON parser pydantic ใน LangChain
บทสรุป
หากต้องการใช้ตัวแยกวิเคราะห์ JSON pydantic ใน LangChain เพียงติดตั้งโมดูล LangChain และ OpenAI เพื่อเชื่อมต่อกับทรัพยากรและไลบรารี หลังจากนั้น ให้นำเข้าไลบรารี เช่น OpenAI และ pydantic เพื่อสร้างโมเดลพื้นฐานและตรวจสอบข้อมูลในรูปแบบ JSON หลังจากสร้างโมเดลพื้นฐานแล้ว ให้รันฟังก์ชัน parse() จากนั้นฟังก์ชันจะส่งคืนคำตอบสำหรับพรอมต์ โพสต์นี้สาธิตกระบวนการใช้ pydantic JSON parser ใน LangChain