“แพนด้า” เป็นภาษาที่ยอดเยี่ยมสำหรับการวิเคราะห์ข้อมูล เนื่องจากระบบนิเวศที่ยอดเยี่ยมของแพ็คเกจหลามที่มีข้อมูลเป็นศูนย์กลาง ทำให้การวิเคราะห์และนำเข้าปัจจัยทั้งสองทำได้ง่ายขึ้น ค่าเบี่ยงเบนมาตรฐานคือค่าเบี่ยงเบน 'ปกติ' ที่ได้มาจากค่าเฉลี่ย มีการใช้งานเป็นจำนวนมาก เนื่องจากจะส่งกลับหน่วยวัดเดิมของดาต้าเฟรม แพนด้าใช้ std() สำหรับการคำนวณค่าเบี่ยงเบนมาตรฐาน ค่าเบี่ยงเบนมาตรฐานสามารถคำนวณได้จากค่าที่กำหนดซึ่งสามารถอยู่ใน dataframe ในรูปแบบของแถวหรือคอลัมน์ เราจะดำเนินการทุกวิถีทางที่เป็นไปได้ในการใช้ค่าเบี่ยงเบนมาตรฐานของแพนด้า สำหรับการใช้งานโค้ด เราจะใช้เครื่องมือ 'spyder' ตามที่เขียนในสภาพแวดล้อมที่เป็นมิตรกับงูหลาม
ไวยากรณ์
“df.std .” ( ) ”
ไวยากรณ์ต่อไปนี้ใช้สำหรับคำนวณค่าเบี่ยงเบนมาตรฐานในดาต้าเฟรม “df” ในดาต้าเฟรมเป็นตัวย่อของ “ดาต้าเฟรม” ส่วนเบี่ยงเบนมาตรฐานทำอะไร? มันวัดว่าข้อมูลที่ต้องการขยายออกไปมากเพียงใด ยิ่งค่าสูงขยายมากเท่าใด ค่าเบี่ยงเบนมาตรฐานก็จะยิ่งสูงขึ้นเท่านั้น
กลับ
ค่าเบี่ยงเบนมาตรฐานของแพนด้าจะส่งกลับ dataframe หากระบุระดับตามความต้องการ
โปรดทราบว่าฟังก์ชัน 'std()' จะละเว้นค่า 'NaN' ใน 'df' โดยอัตโนมัติในขณะที่คำนวณค่าเบี่ยงเบนมาตรฐานของแพนด้า “NaN” สามารถอธิบายได้ว่า “ไม่ใช่ตัวเลข” ซึ่งหมายความว่าไม่มีค่าที่กำหนดให้กับค่าใดค่าหนึ่ง
ต่อไปนี้เป็นวิธีการที่จะดำเนินการกับตัวอย่างของค่าเบี่ยงเบนมาตรฐานของแพนด้า:
-
- การคำนวณค่าเบี่ยงเบนมาตรฐานของ Pandas ในคอลัมน์เดียว
- การคำนวณค่าเบี่ยงเบนมาตรฐานของ Pandas ในหลายคอลัมน์
- การคำนวณค่าเบี่ยงเบนมาตรฐานของ Pandas ของคอลัมน์ตัวเลขทั้งหมด
- ส่วนเบี่ยงเบนมาตรฐานของแพนด้าโดยใช้แกน = 1
- ส่วนเบี่ยงเบนมาตรฐานของแพนด้าโดยใช้แกน = 0
การสร้าง Dataframe สำหรับการคำนวณค่าเบี่ยงเบนมาตรฐานใน Pandas
ขั้นแรก เปิดซอฟต์แวร์ 'สไปเดอร์' ตอนนี้นำเข้าไลบรารีแพนด้าเป็น pd เราจะสร้าง dataframe ที่ประกอบด้วยกระดานคะแนนที่มีคำว่า 'x', 'y' และ 'z' โดยมีคะแนนเป็น '22', '10', '11', '16', '12', '45' ”, “36” และ “40” เรามีค่าช่วยเหลือของพวกเขาเป็น '8', '9', '13', '7', '22', '24', '4' และ '6' ด้วยเช่นกันโดยมีค่าของการรีบาวน์เป็น '17', ' 14”, “3”, 5”, “9”, “8”, “7” และ “4”
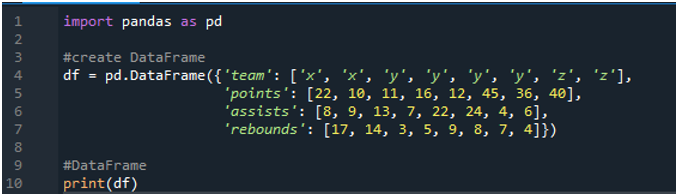
จอแสดงผลจะแสดง dataframe ที่สร้างขึ้นตามค่าที่กำหนดในโค้ด:

ตัวอย่าง # 01: การคำนวณค่าเบี่ยงเบนมาตรฐานของ Pandas ในคอลัมน์เดียว
ในตัวอย่างนี้ เราจะคำนวณค่าเบี่ยงเบนมาตรฐานของคอลัมน์เดียวในดาต้าเฟรมของแพนด้า dataframe มีค่าของทีมเป็น 'u', 'v' และ 'b' โดยมีคะแนนเป็น '44', '33', '22', '44', '45', '88', '96 ” และ “78” ค่าของแอสซิสต์คือ “7”,8”, “9”, “10”, “11”, “14”, “18” และ “17” มีค่าการรีบาวด์เป็น “11”, “ 9”, “8”, “7”, “6”, “5”, “4” และ “3” เลือกคอลัมน์ 'คะแนน' จาก dataframe เพื่อคำนวณค่าเบี่ยงเบนมาตรฐานของคอลัมน์เดียว
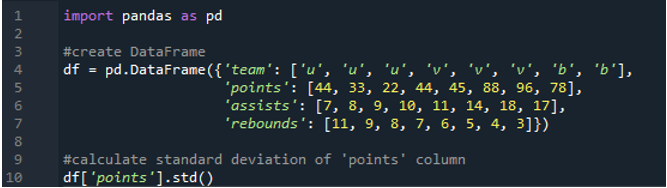
ผลลัพธ์แสดงค่าเบี่ยงเบนมาตรฐานที่คำนวณจากคอลัมน์ 'คะแนน':

ตัวอย่าง # 02: การคำนวณค่าเบี่ยงเบนมาตรฐานของ Pandas ในหลายคอลัมน์
ในตัวอย่างนี้ เราจะดำเนินการคำนวณค่าเบี่ยงเบนมาตรฐานของแพนด้าในหลายคอลัมน์ ในกรอบข้อมูลนี้ ข้อมูลจะเป็นอีกครั้งของป้ายบอกคะแนนกีฬาที่มีค่าของทีมเป็น 'n', 'w' และ 't' โดยมีคะแนนเป็น '33', '22', '66', '55', “44”, “88”, “99” และ “77” ช่วยเป็น '9', '7', '8', '11', '16', '14', '12' และ '13' และรีบาวน์เป็น '5', '8', '1', ' 2”, “3”, “4”, “6” และ “7” ที่นี่เราจะคำนวณค่าเบี่ยงเบนมาตรฐานของ 'จุด' และ 'รีบาวด์' สองคอลัมน์โดยใช้ฟังก์ชัน std() ที่ใช้กับดาต้าเฟรม
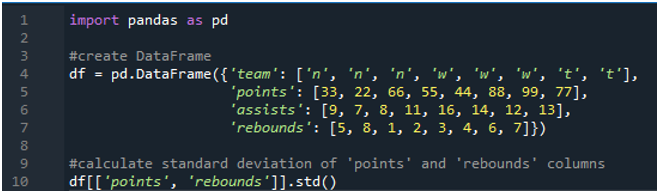
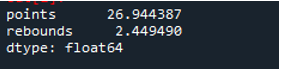
อย่างที่เราเห็น ผลลัพธ์แสดงค่าเบี่ยงเบนมาตรฐานขึ้นมาเป็น 26.944387 ในคอลัมน์คะแนน และ 2.449490 ในคอลัมน์รีบาวด์ตามลำดับ
ตัวอย่าง # 03: การคำนวณค่าเบี่ยงเบนมาตรฐานของ Pandas ของคอลัมน์ตัวเลขทั้งหมด
ตอนนี้เราได้เรียนรู้วิธีคำนวณค่าเบี่ยงเบนมาตรฐานของแถวเดียวและหลายแถวแล้ว จะเป็นอย่างไรหากเราไม่ต้องการระบุชื่อคอลัมน์ทั้งหมดใน dataframe และคำนวณ dataframe ทั้งหมด สิ่งนี้เป็นไปได้ด้วยการใช้ฟังก์ชันอย่างง่ายของค่าเบี่ยงเบนมาตรฐานของแพนด้าสำหรับการคำนวณดาต้าเฟรมที่สมบูรณ์ในผลลัพธ์ dataframe ที่นี่ประกอบด้วย 'l', 'm' และ 'o' โดยมีค่าการให้คะแนน '33', '36', '79', '78', '58', '55' และสองทีมทำคะแนนเท่ากัน นั่นคือ “25” ผู้ช่วยคือ '1', '2', '3', '4', '6', '9', '5' และ '7' และรีบาวน์เป็น '14', '10', '2' , “5”, “8”, “3”, “6” และ “9” เราสามารถคำนวณค่าเบี่ยงเบนคอลัมน์มาตรฐานทั้งหมดโดยแพนด้าใน dataframe โดยใช้ฟังก์ชัน pandas “std()”
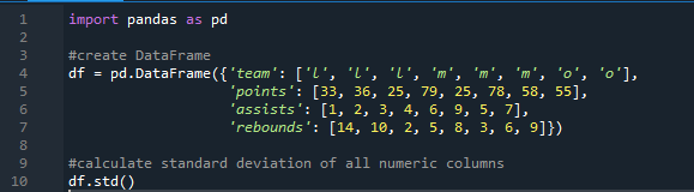
จอแสดงผลมีค่าเบี่ยงเบนมาตรฐานที่คำนวณได้ของ 'df' ทั้งหมดที่แสดงด้านล่าง เรายังสังเกตได้ว่าแพนด้าไม่ได้คำนวณค่าเบี่ยงเบนมาตรฐานของคอลัมน์แรก ซึ่งก็คือ 'ทีม' เพราะมันไม่ใช่คอลัมน์ตัวเลข
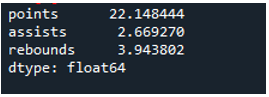
ตัวอย่าง # 04: การเบี่ยงเบนมาตรฐานของ Pandas โดยใช้แกน = 0
ในตัวอย่างนี้ dataframes มีทีมกีฬาเป็น 'g', 'h' และ 'k' พร้อมข้อมูลเพิ่มเติม ในที่นี้ เราจะคำนวณค่าเบี่ยงเบนมาตรฐานโดยใช้แกนเป็น “0” ซึ่งเป็นพารามิเตอร์ที่ใช้ในค่าเบี่ยงเบนมาตรฐานของแพนด้า อาร์กิวเมนต์นี้คำนวณค่าเบี่ยงเบนมาตรฐานของคอลัมน์ดาต้าเฟรม
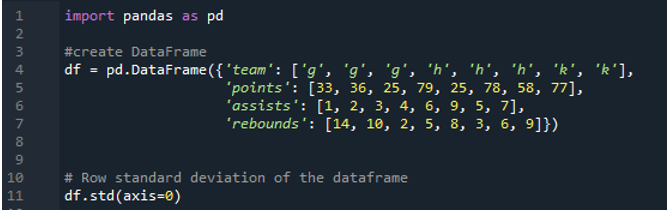
ผลลัพธ์ต่อไปนี้แสดงผลลัพธ์ในคอลัมน์ของค่าเบี่ยงเบนมาตรฐานที่คำนวณได้ คอลัมน์คะแนนมีค่าเบี่ยงเบนมาตรฐานที่คำนวณได้เป็น “24.0313062” คอลัมน์ช่วยเหลือมีค่าเบี่ยงเบนมาตรฐานที่คำนวณได้เป็น “2.669270” และค่าเบี่ยงเบนมาตรฐานที่คำนวณได้ของคอลัมน์รีบาวด์จะแสดงเป็น “3.943802”
ตัวอย่าง # 05: การเบี่ยงเบนมาตรฐานของ Pandas โดยใช้ Axis = 1
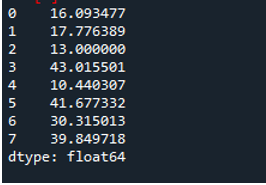
เราจะใช้พารามิเตอร์แกนที่กำหนดเป็น “1” เพื่อคำนวณค่าเบี่ยงเบนมาตรฐานในแพนด้า แกน “1” สามารถสร้างความแตกต่างอะไรได้บ้าง อาร์กิวเมนต์แกน '1' จะคำนวณค่าเบี่ยงเบนมาตรฐานตามแถวของค่าตัวเลขในดาต้าเฟรม ดาต้าเฟรมมีสามทีมในชื่อ “s”, “d” และ “e” โดยเพิ่มคอลัมน์ข้อมูลที่สร้างขึ้นเป็นจุดของทีม แอสซิสต์ของทีม และการรีบาวน์ของทีม ทิศทางทั้งหมดถูกกำหนดด้วยค่าที่แตกต่างกันใน dataframe พารามิเตอร์แกนนี้เป็นตัวเปลี่ยนเกม เมื่อถึงเวลา เราต้องทำงานกับข้อมูลที่เราต้องการให้มันอยู่ในคอลัมน์บวกจุดที่คำนวณจากค่าเบี่ยงเบนมาตรฐานที่ดำเนินการ
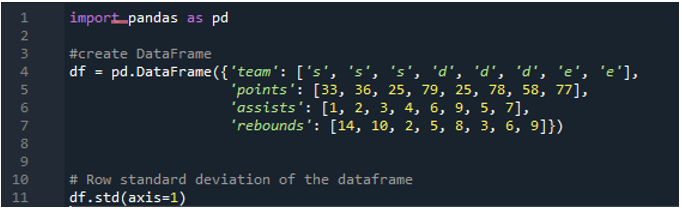
ผลลัพธ์ต่อไปนี้แสดงค่าเบี่ยงเบนมาตรฐานที่คำนวณในแถวของดาต้าเฟรม:
บทสรุป
ส่วนเบี่ยงเบนมาตรฐานของ Pandas เป็นฟังก์ชันทางเทคนิค ซึ่งเป็นฟังก์ชันที่เป็นประโยชน์มาก เนื่องจากพบค่าเบี่ยงเบนมาตรฐานของข้อตกลงความกระตือรือร้นของ dataframes ของแพนด้า ในบทบรรณาธิการนี้ เราได้ศึกษาวิธีการคำนวณค่าเบี่ยงเบนมาตรฐานในแพนด้า เราได้ทำการคำนวณคอลัมน์เดียวของค่าเบี่ยงเบนมาตรฐานและหลายคอลัมน์แล้ว และยังคำนวณค่าเบี่ยงเบนมาตรฐานของดาต้าเฟรมทั้งหมดด้วย กลยุทธ์ทั้งหมดทำงานได้ดีตราบใดที่ใช้อย่างสม่ำเสมอและให้ผลลัพธ์ที่ต้องการ