LangChain เป็นเฟรมเวิร์กที่สามารถใช้เพื่อนำเข้าไลบรารีและการขึ้นต่อกันสำหรับการสร้างแบบจำลองภาษาขนาดใหญ่หรือ LLM โมเดลภาษาใช้หน่วยความจำเพื่อจัดเก็บข้อมูลหรือประวัติในฐานข้อมูลเป็นการสังเกตเพื่อรับบริบทของการสนทนา หน่วยความจำได้รับการกำหนดค่าให้จัดเก็บข้อความล่าสุด เพื่อให้โมเดลสามารถเข้าใจข้อความแจ้งที่ไม่ชัดเจนที่ผู้ใช้ให้ไว้
บล็อกนี้จะอธิบายกระบวนการใช้หน่วยความจำใน LLMChain ผ่าน LangChain
วิธีใช้หน่วยความจำใน LLMChain ผ่าน LangChain
หากต้องการเพิ่มหน่วยความจำและใช้ใน LLMChain ผ่าน LangChain คุณสามารถใช้ไลบรารี ConversationBufferMemory ได้โดยการนำเข้าจาก LangChain
หากต้องการเรียนรู้กระบวนการใช้หน่วยความจำใน LLMChain ผ่าน LangChain ให้ปฏิบัติตามคำแนะนำต่อไปนี้:
ขั้นตอนที่ 1: ติดตั้งโมดูล
ขั้นแรก ให้เริ่มกระบวนการใช้หน่วยความจำโดยการติดตั้ง LangChain โดยใช้คำสั่ง pip:
pip ติดตั้ง langchain
ติดตั้งโมดูล OpenAI เพื่อรับการขึ้นต่อกันหรือไลบรารีเพื่อสร้าง LLM หรือโมเดลการแชท:
pip ติดตั้ง openai
ตั้งค่าสภาพแวดล้อม สำหรับ OpenAI โดยใช้คีย์ API โดยการนำเข้าระบบปฏิบัติการและไลบรารี getpass:
นำเข้าเรานำเข้า getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('คีย์ OpenAI API:')
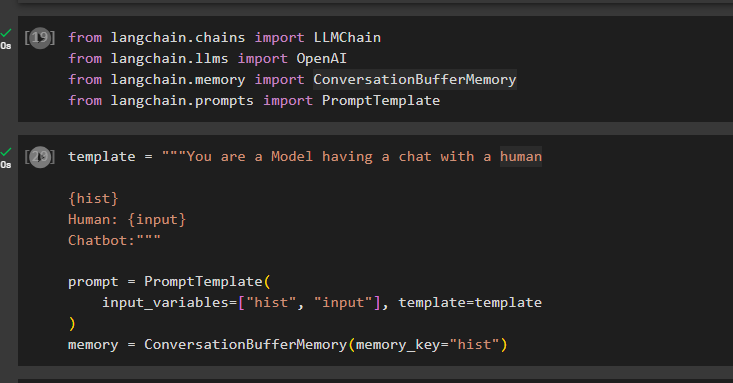
ขั้นตอนที่ 2: การนำเข้าไลบรารี
หลังจากตั้งค่าสภาพแวดล้อมแล้ว เพียงนำเข้าไลบรารีเช่น ConversationBufferMemory จาก LangChain:
จาก langchain.chains นำเข้า LLMChainจาก langchain.llms นำเข้า OpenAI
จาก langchain.memory นำเข้า ConversationBufferMemory
จาก langchain.prompts นำเข้า PromptTemplate
กำหนดค่าเทมเพลตสำหรับพรอมต์โดยใช้ตัวแปร เช่น “input” เพื่อรับการสืบค้นจากผู้ใช้ และ “hist” เพื่อจัดเก็บข้อมูลในหน่วยความจำบัฟเฟอร์:
template = '''คุณเป็นนางแบบที่กำลังสนทนากับมนุษย์{ประวัติ}
มนุษย์: {อินพุต}
แชทบอท:'''
prompt = พร้อมต์เทมเพลต (
input_variables=['hist', 'input'], template=template
)
หน่วยความจำ = ConversationBufferMemory (memory_key = 'hist')
ขั้นตอนที่ 3: การกำหนดค่า LLM
เมื่อสร้างเทมเพลตสำหรับการสืบค้นแล้ว ให้กำหนดค่าวิธี LLMChain() โดยใช้พารามิเตอร์หลายตัว:
llm = OpenAI()llm_chain = LLMChain(
ไอแอลเอ็ม=ไอแอลเอ็ม,
พร้อมท์=พร้อมท์,
รายละเอียด=จริง
หน่วยความจำ = ความทรงจำ
)
ขั้นตอนที่ 4: ทดสอบ LLMChain
หลังจากนั้น ทดสอบ LLMChain โดยใช้ตัวแปรอินพุตเพื่อรับพรอมต์จากผู้ใช้ในรูปแบบข้อความ:
llm_chain.predict(input='สวัสดีเพื่อน') 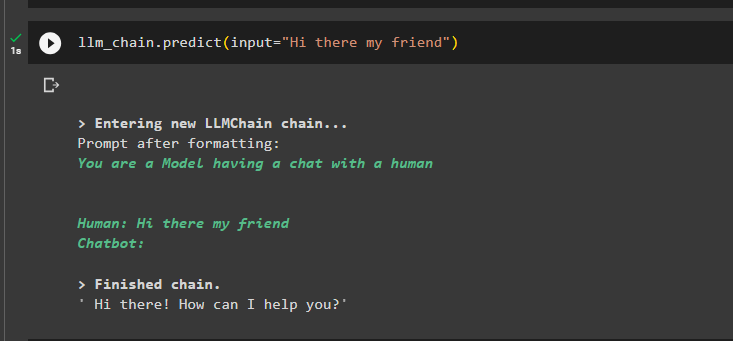
ใช้อินพุตอื่นเพื่อรับข้อมูลที่จัดเก็บไว้ในหน่วยความจำเพื่อแยกเอาต์พุตโดยใช้บริบท:
llm_chain.predict(input='ดี! ฉันสบายดี - สบายดีไหม') 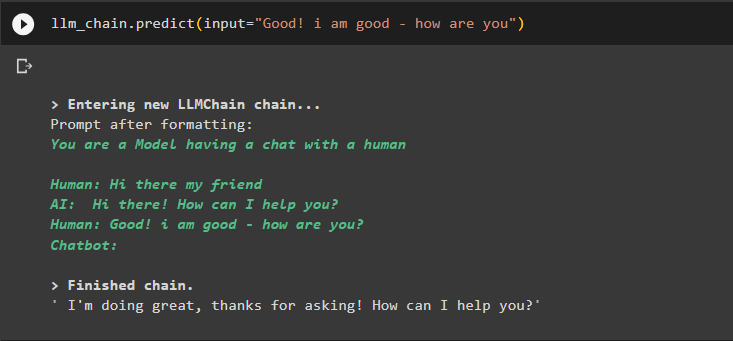
ขั้นตอนที่ 5: การเพิ่มหน่วยความจำให้กับโมเดลการแชท
สามารถเพิ่มหน่วยความจำลงใน LLMChain ที่ใช้โมเดลการแชทได้โดยการนำเข้าไลบรารี:
จาก langchain.chat_models นำเข้า ChatOpenAIจาก langchain.schema นำเข้า SystemMessage
จาก langchain.prompts นำเข้า ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
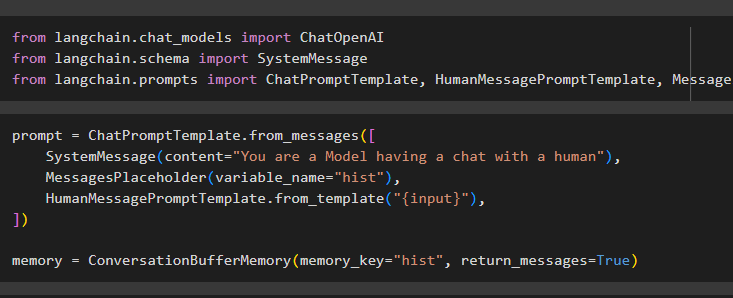
กำหนดค่าเทมเพลตพรอมต์โดยใช้ ConversationBufferMemory() โดยใช้ตัวแปรที่แตกต่างกันเพื่อตั้งค่าอินพุตจากผู้ใช้:
prompt = ChatPromptTemplate.from_messages([SystemMessage(content='คุณเป็นนางแบบที่กำลังสนทนากับมนุษย์'),
MessagesPlaceholder(variable_),
HumanMessagePromptTemplate.from_template('{input}'),
])
หน่วยความจำ = ConversationBufferMemory (memory_key = 'hist', return_messages = True)
ขั้นตอนที่ 6: การกำหนดค่า LLMChain
ตั้งค่าเมธอด LLMChain() เพื่อกำหนดค่าโมเดลโดยใช้อาร์กิวเมนต์และพารามิเตอร์ที่แตกต่างกัน:
llm = ChatOpenAI()chat_llm_chain = LLMChain(
ไอแอลเอ็ม=ไอแอลเอ็ม,
พร้อมท์=พร้อมท์,
รายละเอียด=จริง
หน่วยความจำ = ความทรงจำ
)
ขั้นตอนที่ 7: ทดสอบ LLMChain
ในตอนท้าย เพียงทดสอบ LLMChain โดยใช้อินพุต เพื่อให้โมเดลสามารถสร้างข้อความตามพร้อมท์:
chat_llm_chain.predict(input='สวัสดีเพื่อน') 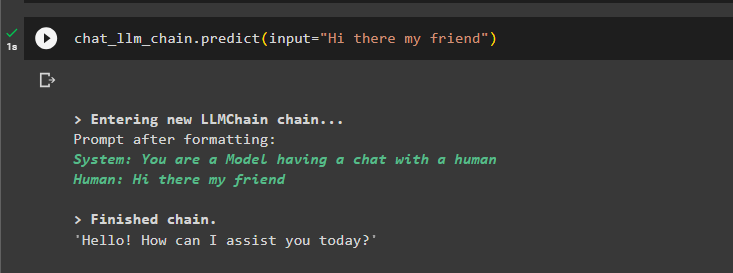
โมเดลได้จัดเก็บการสนทนาก่อนหน้านี้ไว้ในหน่วยความจำและแสดงก่อนผลลัพธ์จริงของการสืบค้น:
llm_chain.predict(input='ดี! ฉันสบายดี - สบายดีไหม') 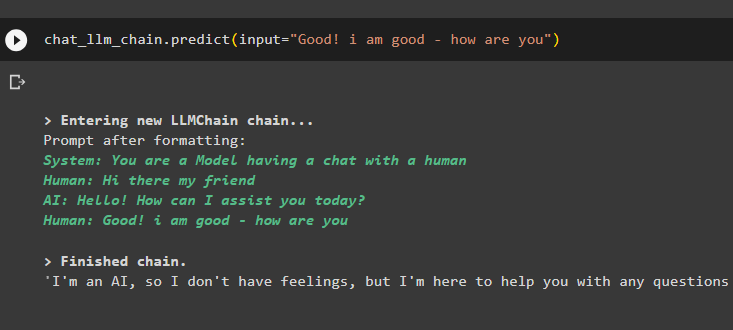
นั่นคือทั้งหมดที่เกี่ยวกับการใช้หน่วยความจำใน LLMChain โดยใช้ LangChain
บทสรุป
หากต้องการใช้หน่วยความจำใน LLMChain ผ่านเฟรมเวิร์ก LangChain เพียงติดตั้งโมดูลเพื่อตั้งค่าสภาพแวดล้อมเพื่อรับการขึ้นต่อกันจากโมดูล หลังจากนั้น เพียงนำเข้าไลบรารีจาก LangChain เพื่อใช้หน่วยความจำบัฟเฟอร์สำหรับจัดเก็บการสนทนาก่อนหน้า ผู้ใช้ยังสามารถเพิ่มหน่วยความจำให้กับโมเดลการแชทโดยการสร้าง LLMChain จากนั้นทดสอบเชนโดยระบุอินพุต คู่มือนี้ได้อธิบายรายละเอียดเกี่ยวกับกระบวนการใช้หน่วยความจำใน LLMChain ผ่าน LangChain