Elasticsearch เป็นโซลูชันที่แข็งแกร่งและเป็นที่ชื่นชอบในการจัดเก็บข้อมูลขนาดใหญ่ ไม่มีโครงสร้าง และกึ่งโครงสร้าง เป็นฐานข้อมูล NoSQL ล้วนๆ และใช้วิธีการที่แตกต่างกันโดยสิ้นเชิงในการจัดเก็บ จัดการ และดึงข้อมูล มันเก็บข้อมูลในเอกสารในรูปแบบ JSON และใช้ API ที่เหลือเพื่อดำเนินการต่าง ๆ กับข้อมูลที่เก็บไว้
ในบล็อกนี้ เราจะสาธิต:
- Elasticsearch ทำงานอย่างไรในการจัดเก็บและค้นหาข้อมูล
- เอกสาร Elasticsearch คืออะไร?
- วิธีการจัดเก็บข้อมูลในเอกสาร Elasticsearch?
Elasticsearch ทำงานอย่างไรในการจัดเก็บและค้นหาข้อมูล
ส่วนประกอบหลักหรือลำดับชั้นของ Elasticsearch ที่ใช้ในการจัดเก็บข้อมูลมีดังต่อไปนี้:
- เอกสาร: เอกสารเป็นส่วนหลักของ Elasticsearch ที่เก็บข้อมูลในรูปแบบ JSON ชอบ
- ดัชนี: ดัชนีเรียกว่าดัชนี เป็นชุดเอกสาร เช่นเดียวกับใน SQL จะเรียกว่าฐานข้อมูล
- ดัชนีกลับด้าน: รองรับการค้นหาข้อความแบบเต็มที่รวดเร็วมาก มันเก็บคำเป็นดัชนีและชื่อของเอกสารเป็นข้อมูลอ้างอิง
เอกสาร Elasticsearch คืออะไร?
เอกสาร Elasticsearch เป็นหน่วยเก็บข้อมูลในรูปแบบ JSON เช่นเดียวกับในฐานข้อมูลเชิงสัมพันธ์ เอกสารสามารถอ้างถึงเป็นตารางหรือแถวของฐานข้อมูลที่จัดเก็บไว้ในดัชนีบางตัว ดัชนีสามารถมีหลายเอกสารและเรียกว่าฐานข้อมูลที่มีหลายตาราง โดยปกติจะจัดเก็บโครงสร้างข้อมูลที่ซับซ้อนและฆ่าเชื้อข้อมูลในรูปแบบ JSON
นอกจากนี้ แต่ละเอกสารยังสามารถมีหลายฟิลด์ซึ่งได้แก่ “ คีย์: ค่า ” จับคู่เพื่อจัดเก็บข้อมูลเช่นเดียวกับตารางที่มีหลายคอลัมน์หรือหลายฟิลด์ในฐานข้อมูลเชิงสัมพันธ์ จากนั้น ควรจัดทำดัชนีคู่คีย์-ค่าเหล่านี้เพื่อกำหนดการจับคู่เอกสาร จากนั้นการแมปจะกำหนดประเภทข้อมูลของเอกสารตามข้อมูลฟิลด์ เช่น ข้อความ ทศนิยม จุดภูมิศาสตร์ เวลา และอื่นๆ อีกมากมาย
Elasticsearch ไม่เคยผูกมัดให้เรากำหนดโครงสร้างฟิลด์ดัชนีไว้ล่วงหน้า และเอกสารสามารถมีโครงสร้างฟิลด์ที่แตกต่างกันในดัชนีได้ อย่างไรก็ตาม หากการแมปของฟิลด์ถูกกำหนดสำหรับประเภทข้อมูลเฉพาะ เอกสารของ Elasticsearch ทั้งหมดในดัชนีจะต้องเป็นไปตามประเภทการแมปเดียวกัน หากต้องการดูการทำงานของเอกสารเพื่อเก็บข้อมูลใน Elasticsearch ให้ไปที่ส่วนถัดไป
วิธีการจัดเก็บข้อมูลในเอกสาร Elasticsearch?
ในการจัดเก็บข้อมูลใน Elasticsearch ผู้ใช้ต้องสร้างดัชนีก่อน จากนั้นระบุฟิลด์ที่จะเก็บข้อมูลในเอกสาร Elasticsearch สำหรับการสาธิต ให้ทำตามขั้นตอนที่ระบุไว้
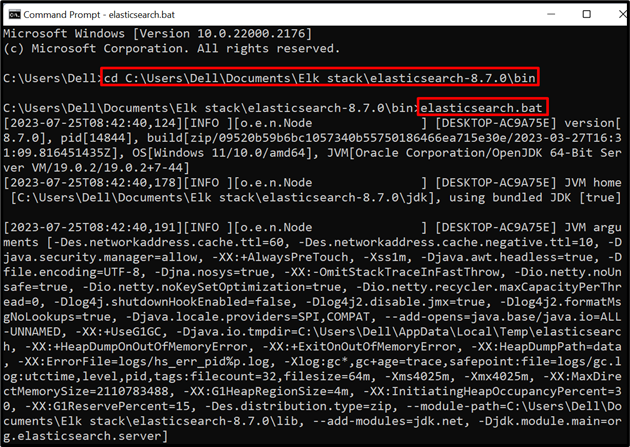
ขั้นตอนที่ 1: เริ่ม Elasticsearch
ในการเรียกใช้ฐานข้อมูลหรือกลไกของ Elasticsearch บนระบบ ให้เปิดเทอร์มินัลระบบ เช่น Command Prompt หลังจากนั้น เข้าไปที่ “ ถัง ” โฟลเดอร์ของ Elasticsearch ผ่าน “ ซีดี ' สั่งการ:
ซีดี C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
หลังจากนั้น เรียกใช้งานแบตช์ไฟล์ของ Elasticsearch เพื่อเรียกใช้ฐานข้อมูลบนระบบ:
elasticsearch.bat
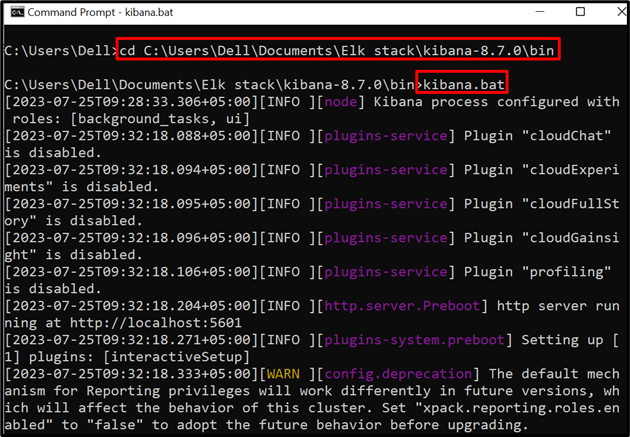
ขั้นตอนที่ 2: เริ่ม Kibana
ถัดไป เรียกใช้ Kibana บนระบบ โดยไปที่ “ ถัง ” โฟลเดอร์จากพรอมต์คำสั่ง:
ซีดี C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
ถัดไป เรียกใช้คำสั่งด้านล่างเพื่อเริ่มดำเนินการ Kibana:
kibana.bat
บันทึก: หากคุณยังไม่ได้ติดตั้งและตั้งค่า Elasticsearch และ Kibana บนระบบ ให้ไปที่โพสต์ของเรา และดูขั้นตอนทีละขั้นตอนเพื่อติดตั้งบนระบบ
สำหรับ Elasticsearch โปรดไปที่ “ ติดตั้งและตั้งค่า Elasticsearch ด้วย .zip บน Windows ' บทความ. ในการตั้งค่า Kibana บน Windows ให้ทำตาม “ ตั้งค่า Kibana สำหรับ Elasticsearch ' บทความ.
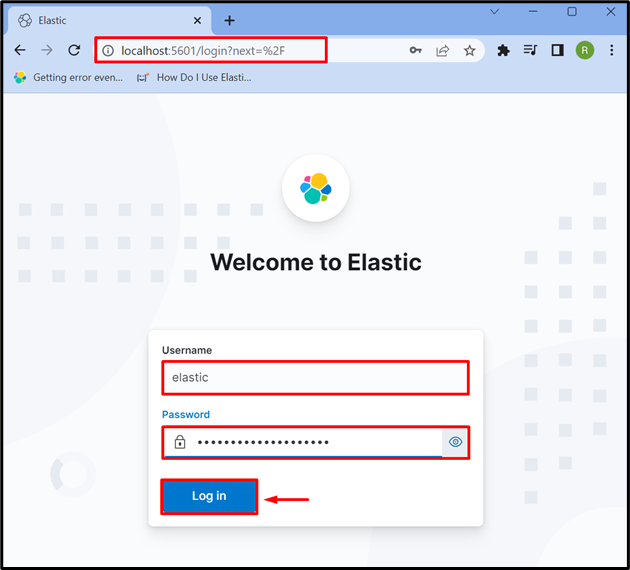
ขั้นตอนที่ 3: เข้าสู่ระบบ Kibana
หลังจากเริ่มต้น Kibana บนระบบแล้ว ให้ไปที่ที่อยู่เริ่มต้นของ Kibana “ localhost:5601 ” ในเบราว์เซอร์ และระบุข้อมูลรับรองการเข้าสู่ระบบของ Elasticsearch เช่น “ ยืดหยุ่น ” ผู้ใช้และรหัสผ่าน หลังจากนั้นให้กดปุ่ม “ เข้าสู่ระบบ ' ปุ่ม:
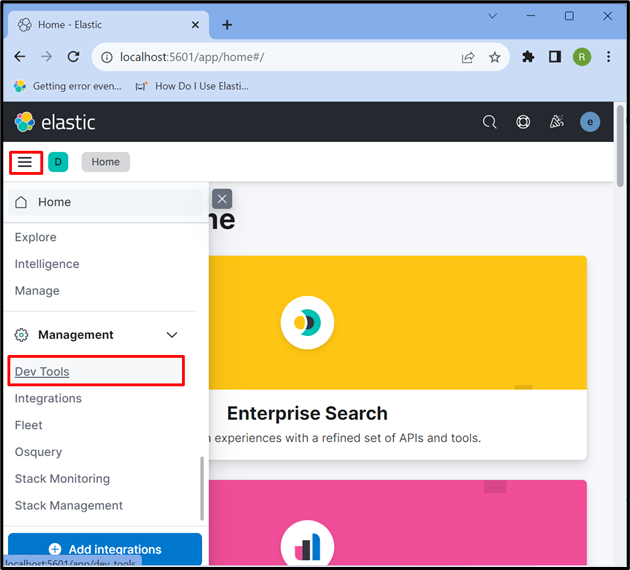
ขั้นตอนที่ 4: เปิด Kibana “Dev Tool”
หลังจากนั้นให้คลิกที่ “ สามแถบแนวนอน ” ไอคอนและเปิด Kibana “ เครื่องมือพัฒนา ” เพื่อใช้ API เพื่อจัดเก็บ ดึงข้อมูล และอัปเดตข้อมูล:
ขั้นตอนที่ 5: สร้างดัชนี
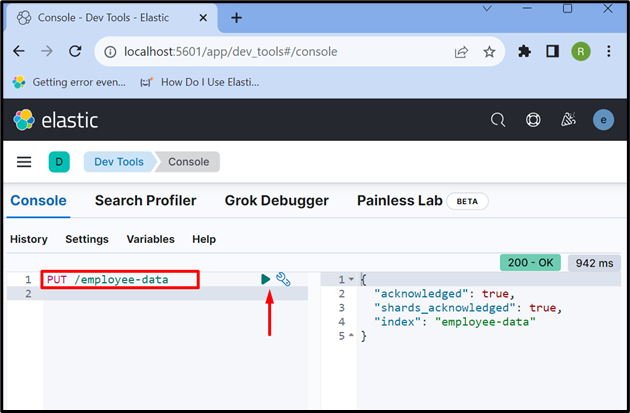
ตอนนี้ สร้างดัชนีใหม่โดยใช้ “ PUT /<ชื่อดัชนี> คำขอ API:
ใส่ / ข้อมูลพนักงาน
ผลลัพธ์แสดงว่า “ ข้อมูลพนักงาน ” สร้างดัชนีสำเร็จแล้ว:
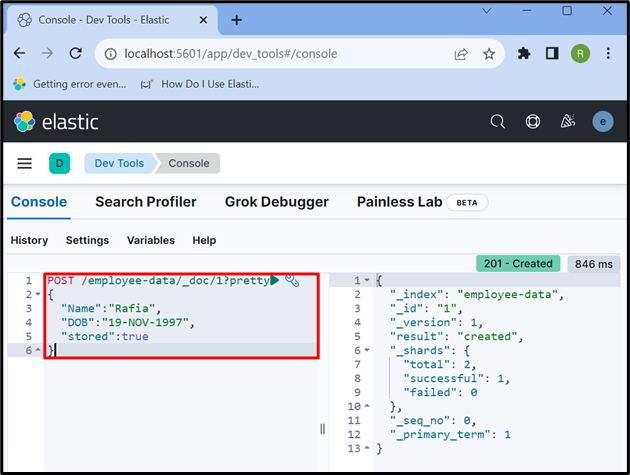
ขั้นตอนที่ 6: ใส่ข้อมูลในเอกสาร
ตอนนี้ใช้ ' โพสต์ ” API เพื่อเก็บข้อมูลในดัชนี ในคำขอด้านล่าง “ ข้อมูลพนักงาน ” เป็นดัชนีของ Elasticsearch “ _doc ” ใช้เพื่อเก็บข้อมูลในเอกสารของ Elasticsearch และ “ 1 ” คือรหัส:
โพสต์ / ข้อมูลพนักงาน / _doc / 1 ?สวย{
'ชื่อ' : 'ต้นปาล์มชนิดหนึ่ง' ,
'ทบ.' : '19-พ.ย.-2540' ,
'เก็บไว้' :จริง
}
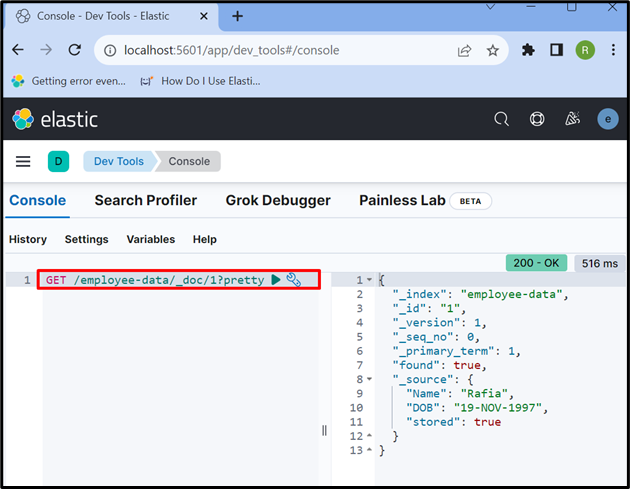
ขั้นตอนที่ 7: ดึงข้อมูลจากเอกสาร Elasticsearch
ในการเข้าถึงข้อมูลจากดัชนีหรือเอกสาร Elasticsearch ให้ใช้ปุ่ม “ รับ ” API ตามที่ใช้ด้านล่าง:
รับ / ข้อมูลพนักงาน / _doc / 1 ?สวย
ผลลัพธ์แสดงว่าเราได้แยกข้อมูลจากเอกสาร Elasticsearch ที่มี id “ 1 ”:
นั่นคือทั้งหมดที่เกี่ยวกับเอกสาร Elasticsearch
บทสรุป
เอกสาร Elasticsearch มักจะใช้เพื่อเก็บข้อมูลในรูปแบบ JSON เช่นเดียวกับในฐานข้อมูลเชิงสัมพันธ์ เอกสารสามารถอ้างถึงเป็นแถวที่จัดเก็บไว้ในดัชนีบางตัว ดัชนีเหล่านี้สามารถมีเอกสารได้หลายชุด เช่นเดียวกับฐานข้อมูลที่มีตารางต่างกัน เอกสารเหล่านี้มีหลายฟิลด์ซึ่งได้แก่ “ คีย์: ค่า ” จับคู่เพื่อเก็บข้อมูล บทความนี้แสดงให้เห็นว่าเอกสารของ Elasticsearch คืออะไรและทำงานอย่างไรใน Elasticsearch